Avec la mise à disposition publique de ChatGPT 3.5 à l’automne 2022 au plus tard, l’intelligence artificielle au sens de grands modèles linguistiques ( LLM) est sur toutes les lèvres. On oublie souvent que ce n’est que l’aboutissement provisoire de plusieurs décennies de développement d’intelligences artificielles qui, malgré leur grand potentiel, présentent encore de nombreuses limites. Pour le médecin praticien, la question est de savoir comment cette technologie peut être utilisée de manière judicieuse dans le quotidien clinique – et comment il vaut mieux ne pas l’utiliser.
Vous pouvez passer le test de FMC sur notre plateforme d’apprentissage après avoir lu le matériel recommandé. Pour ce faire, veuillez cliquer sur le bouton suivant :
Avec la mise à disposition publique de ChatGPT 3.5 à l’automne 2022 au plus tard, l’intelligence artificielle au sens de grands modèles linguistiques ( LLM) est sur toutes les lèvres. On oublie souvent que ce n’est que l’aboutissement provisoire de plusieurs décennies de développement d’intelligences artificielles qui, malgré leur grand potentiel, présentent encore de nombreuses limitations.
Pour le médecin praticien, la question est de savoir comment cette technologie fascinante peut être utilisée de manière judicieuse dans le quotidien clinique – et comment il vaut mieux ne pas l’utiliser. Le présent CME a pour but d’apporter une aide concrète dans ce domaine.
Vignette de cas – 1ère partie
Une patiente de 44 ans se présente au cabinet de son médecin généraliste avec des douleurs abdominales gauches. Les douleurs ont commencé il y a quelques jours et sont maintenant en constante augmentation. La patiente est en bon état général avec des paramètres vitaux stables. Il existe une dolence à la pression dans le bas-ventre gauche avec une tension défensive minimale. Il n’y a pas de fièvre, les valeurs de l’inflammation sont légèrement élevées. Une diverticulite est suspectée.
Le jeune collègue du cabinet de médecine générale est enthousiasmé par les possibilités offertes par les grands modèles linguistiques et souhaite les utiliser dans sa pratique clinique quotidienne.
Bases techniques [1]
Les grands modèles linguistiques (LLM) sont un sous-domaine de l’intelligence artificielle ou de l’apprentissage automatique qui traite du traitement du langage naturel (natural language processing). Ils sont constitués d’un réseau comportant des dizaines de couches (layers) et des milliards, voire probablement des trillions, de connexions (parameters). Cette structure étant similaire à celle d’un cerveau biologique, le terme de “réseau neuronal” s’est imposé.
Le réseau est entraîné sur un vaste corpus de textes, généralement disponible gratuitement sur Internet. Tous les fabricants ne divulguent pas l’étendue exacte des données d’entraînement. L’entraînement est à la fois automatisé (non supervisé) et guidé par l’homme (partiellement supervisé) et nécessite énormément de temps et de ressources. La supervision humaine est nécessaire pour améliorer la qualité de l’apprentissage et contrôler que le langage négatif ou agressif ne prédomine pas. En même temps, cette supervision humaine est aussi une zone de problèmes, car les examinateurs sont souvent sous-payés et peuvent ne pas être suffisamment formés.
Pendant l’apprentissage, les données d’apprentissage sont fragmentées (tokenisées) en petits fragments tels que des mots ou de courtes parties de mots et les connexions entre elles sont pondérées dans le réseau. Les liens fréquents sont renforcés et les liens rares sont affaiblis. Le réseau développe ainsi une connaissance approfondie de la structure de la langue dans les données d’apprentissage. En fonction des paramètres de base et des données de formation, un réseau peut être spécialisé dans des tâches spécifiques, par exemple la traduction de la langue. Les LLM actuellement en ligne de mire sont pour la plupart des “généralistes” sans spécialisation claire.
| Société Suisse d’Informatique Médicale (SSIM) |
| La Société Suisse d’Informatique Médicale (SSIM) promeut l’étude, le développement et l’utilisation des moyens informatiques dans le domaine de la santé. En tant qu’organisation neutre, nous accordons une grande importance à l’aspect scientifique (efficacité, utilité, adéquation) lors de la diffusion de moyens informatiques dans le quotidien clinique (informatique médicale basée sur les preuves). La SSMI se considère donc comme un partenaire prudent et fiable dans le domaine de l’intégration des systèmes, de la conception des processus, du transfert et de l’utilisation des données dans un écosystème de santé sociotechnique orienté vers les normes. |
| Dans le cadre de ses activités, la SSMI organise chaque année en automne le ehealthsummit suisse. Elle publie également à intervalles réguliers des guides sur des thèmes importants de l’informatique médicale (MENTOR). En septembre 2023, elle a publié un MENTOR sur le thème “LLMs dans le quotidien clinique”, qui a servi de base à cet article [1]. |
| > www.sgmi-ssim.ch |
Une fois la formation terminée, le réseau et les connexions pondérées restent inchangés. Les modifications de base du réseau ne sont plus possibles dans cet état, mais le comportement de réponse peut toujours être réglé. Par exemple, la longueur de la réponse, le style de langage, la répétition des mots et le caractère aléatoire peuvent être réglés.
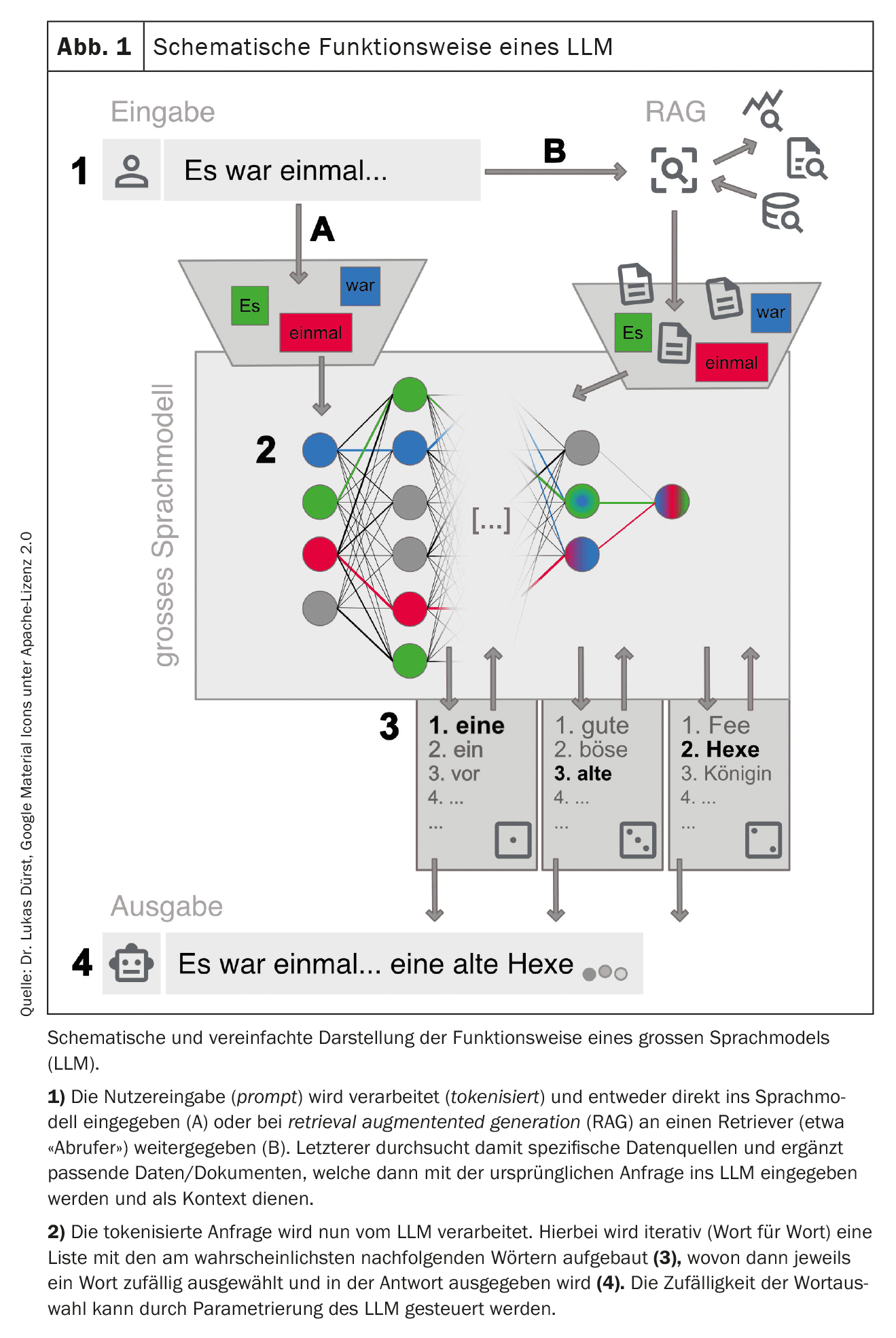
Il est maintenant possible d’interagir avec ce réseau formé. Cela se fait souvent par le biais d’un chat sur une page web ou d’une application pour smartphone, mais des connexions techniques directes via des interfaces web sont également possibles (voir le tableau 1 pour des exemples ). La demande (prompt) est préparée et introduite dans le LLM. Celui-ci génère alors une réponse mot par mot (ou plus précisément : jeton par jeton) de manière itérative. Le mot suivant est sélectionné dans une liste de mots les plus probables. Cette sélection est aléatoire jusqu’à un certain point afin de rendre la génération de texte plus créative (“humaine”). Le degré d’aléa peut être réglé par les fournisseurs de LLM ou influencé par un prompting ciblé, mais il exclut dans tous les cas une reproductibilité totale de la réponse (notamment parce que chaque requête n’est pas traitée par la même instance des LLM disponibles).
Pour obtenir les meilleurs résultats possibles, il est important de suivre certaines règles lors de la requête et de fournir un contexte aussi précis que possible. Ce processus – qui consiste à générer les requêtes les plus optimales possibles – est appelé “prompt engineering ” (tableau 2). Selon le type de requête, les grands fournisseurs peuvent également utiliser des LLM “spécialisés” différents en arrière-plan. La figure 1 donne un aperçu simplifié du fonctionnement d’un LLM.

Avantages et inconvénients
Les LLM modernes parviennent étonnamment bien à imiter un langage semblable à celui des humains. Cette capacité est en principe indépendante du langage d’entrée utilisé, tant que ce langage est disponible en quantité suffisante dans les données d’apprentissage.
D’un point de vue technique, les LLM les plus récents mettent à disposition une grande partie des connaissances libres disponibles sur Internet. Cependant, en raison de son mode de fonctionnement, un LLM ne peut pas développer ses propres concepts et pensées (véritable créativité), mais se contente de recombiner et de restituer les connaissances disponibles dans le corpus de textes.
Remarque : les LLM produisent du langage, pas de la connaissance !
Cependant, le fonctionnement décrit ci-dessus comporte également certains inconvénients dont les utilisateurs doivent être conscients à tout moment. Par exemple, les LLM ont tendance à inventer (halluciner) des réponses plutôt que d’admettre leur ignorance. Cela est dû au fait que dans de tels cas, des mots moins probables sont simplement ajoutés à la réponse, et cela se produit surtout lorsqu’une réponse est basée sur des données d’apprentissage limitées, par exemple pour une maladie rare. Bien que ce risque puisse être réduit par une bonne configuration des modèles, les hallucinations non détectées restent un risque majeur dans l’utilisation des LLM. De plus, les LLM peuvent être influencés négativement de manière directive par un prompting ciblé [2].
En raison de l’absence de compréhension globale et de la sélection aléatoire du jeton suivant, les LLM montrent des difficultés à gérer la logique et les mathématiques. Cela rend difficile la reproductibilité d’une réponse et donc son utilisation dans la recherche et le contexte médico-légal.
Un autre problème des LLM classiques est l’actualité des données, car les connaissances du LLM ne sont plus étendues une fois sa formation terminée. Les LLM modernes offrent la possibilité d’ajouter, lors de la requête, un contexte supplémentaire et actuel issu, par exemple, d’une recherche bibliographique (retrieval augmented generation, RAG), ce qui permet d’atténuer le problème et d’améliorer la fiabilité de la réponse. Dans ce contexte, le LLM peut même fournir des références fiables, ce qu’il ne peut pas faire autrement. L’utilisateur doit donc être conscient de la variante de LLM avec laquelle il communique.
Enfin, il reste toute une série d’aspects juridiques, réglementaires et éthiques, comme les questions de protection des données, de responsabilité et de droits d’auteur, qui ne sont pas encore suffisamment clarifiés au sein de la société et qui laissent planer une grande incertitude sur l’utilisation correcte des LLM, notamment dans le quotidien médical. Il est possible que des systèmes autonomes nationaux offrent une solution partielle à ce problème (notamment en ce qui concerne la protection des données et la législation suisse). Health Info Net AG (HIN) – traditionnellement liée à la sécurité de l’échange de données du système de santé suisse – semble avoir conclu un partenariat avec SwissGPT. Il n’est toutefois pas encore possible d’évaluer la diffusion et l’acceptation sur le marché.
Remarque : tout ce qui est possible n’est pas forcément autorisé !
Domaines d’application
Vignette de cas – Partie 2
Pour plus de sécurité, le jeune collègue encore inexpérimenté consulte un LLM, qui mentionne également la diverticulite comme diagnostic différentiel le plus probable. Le LLM mentionne également une torsion ou un kyste ovarien ainsi que des calculs rénaux comme diagnostics différentiels possibles. L’échographie focalisée donne des résultats compatibles avec une diverticulite. Il n’y a aucun signe de complication locale.
Le LLM propose une antibiothérapie ambulatoire et une coloscopie de contrôle quelques semaines plus tard. Le confrère et la patiente acceptent cette proposition de traitement. La patiente se rétablit en quelques jours sous traitement, comme prévu.
Poser un diagnostic et raisonner en termes de diagnostic
Le fait que le Dr ChatGPT, grâce à ses vastes connaissances, aide les médecins dans le processus de diagnostic et dans les décisions de traitement, semble être une possibilité d’application évidente.
Après tout, les LLM modernes réussissent l’examen d’État de médecine américain (USMLE) avec des scores élevés de plus de 90% avec les LLM les plus récents [3]. Cela n’est pas surprenant, car ces vignettes de cas sont très structurées et fournissent toutes les informations nécessaires pour établir un diagnostic ou répondre à une question. De plus, il est probable que de nombreuses questions étaient déjà présentes dans les données de formation des LLM.
La situation devient plus intéressante lorsque les LLM doivent trouver eux-mêmes des informations sur les patients dans le cadre d’un processus de diagnostic. Dans ce cas, les résultats sont beaucoup moins impressionnants [4]. Cela n’est pas vraiment surprenant non plus, car dans la première phase d’un diagnostic, de nombreuses informations ne sont pas encore disponibles ou ne sont pas disponibles sous forme numérique, alors qu’un LLM a besoin des informations les plus détaillées possibles pour obtenir les meilleurs résultats. De plus, leur faiblesse fondamentale dans le maniement des chiffres rend difficile l’interprétation des signes vitaux et des résultats de laboratoire.
De par son fonctionnement, un LLM est aujourd’hui principalement un moyen d’identifier, à partir d’un ensemble d’informations fournies, des schémas possibles qui restent éventuellement encore cachés au médecin, c’est-à-dire principalement pour le diagnostic différentiel.
L’utilisation à grande échelle dans la pratique clinique quotidienne pour l’aide à la décision est en outre limitée par les exigences en vigueur en matière de responsabilité, de protection des données et de certification en tant que produit médical.
Recommandations de traitement et recherche documentaire
Étant donné que la plupart des directives de traitement sont disponibles en ligne, il n’est pas surprenant que les LLM puissent également émettre des recommandations de traitement conformes aux directives. Le principal problème est la limitation temporelle des données de formation. Les lignes directrices et les résultats d’études les plus récents ne sont souvent pas entraînés dans le LLM. Dans l’exemple concret, il manque manifestement la nouvelle option de traitement “watch & wait” en cas de diverticulite non compliquée et d’absence de facteurs de risque [5]. Dans ce cas, l’avantage de l’actualité réside toujours dans les ouvrages de référence et les bases de données bibliographiques de grande qualité, gérés par la rédaction.
L’impossibilité pour les LLM classiques de citer précisément leurs sources est un autre facteur aggravant. Il sera toujours difficile de savoir à quelles versions de lignes directrices le LLM se réfère et s’il n’a pas mélangé différentes lignes directrices. Dans ce cas, les RAGs mentionnés précédemment peuvent fournir des résultats beaucoup plus fiables. Si elles sont utilisées par exemple pour la recherche dans Pubmed, la pertinence des résultats de recherche peut être considérablement améliorée [6]. Un autre avantage de cette méthode est que les études trouvées peuvent également être fournies au LLM en tant que contexte et que toutes ses fonctionnalités telles que le résumé, la traduction et l’analyse peuvent alors être utilisées dans le travail original.
Les LLM modernes offrent la possibilité de fournir manuellement un contexte supplémentaire lors de la requête. Par exemple, une étude trouvée peut être jointe et ainsi rapidement résumée et analysée. Il convient toutefois de noter qu’il existe une limite à la “taille” d’une requête, en particulier pour les variantes gratuites des LLM. Il convient donc de vérifier la taille réelle de la saisie ou du contexte (context limit). En outre, ces résumés ne sont pas exempts d’hallucinations.
Vignette de cas – Partie 3
Malheureusement, la coloscopie de contrôle effectuée quelques semaines plus tard révèle un diagnostic d’adénocarcinome du côlon sigmoïde sans signe d’imagerie de métastases locales ou à distance (stade I de l’UICC).
Le confrère du cabinet médical n’est pas sûr de la meilleure façon d’annoncer à la jeune mère le résultat peu rassurant de l’examen. Il utilise un LLM pour se préparer à cet entretien difficile.
Pendant l’entretien, il utilise un LLM pour présenter à la patiente les faits médicaux de manière simple et dans sa langue maternelle portugaise. De même, à la demande de la patiente, il fait traduire son rapport médical succinct en portugais par un LLM.
Conduite d’entretiens
A première vue, il semble contraire à toute intuition de demander conseil à une machine dans ce que l’on considère comme la “discipline de prédilection” de l’homme, la communication. Mais comme la fonction principale des LLM est d’imiter le meilleur langage humain possible, cette approche ne semble plus si absurde à première vue. En conséquence, certaines études ont déjà montré que les LLM modernes sont capables de fournir des réponses contenant des éléments d'”empathie”, qui sont ensuite interprétés comme “empathiques” par l’interlocuteur humain [7]. Avec le prompting correspondant, il est possible d’expérimenter différentes techniques de conduite d’entretien et de variantes d’entretien, ce qui peut donner une sécurité supplémentaire aux médecins inexpérimentés. Bien entendu, cela ne dispense pas le médecin d’une communication empathique et directe avec la patiente.
Éducation des patients
Les LLM, lorsqu’ils sont bien formés, sont très efficaces pour présenter des contenus médicaux spécialisés dans un langage simple et compréhensible. Il est donc tout à fait possible d’essayer d’utiliser des outils basés sur les LLM dans l’éducation des patients. Il est toutefois important que le patient continue à être étroitement accompagné par son médecin. Le devoir d’information du médecin ne peut pas être délégué à un LLM.
Traduction
Les LLM peuvent très bien traduire entre différentes langues. Cela fonctionne non seulement avec les langues naturelles, mais aussi avec des constructions linguistiques artificielles comme les langages de programmation. Les LLM qui ont été spécifiquement formés à la traduction (par exemple deepl.com) sont probablement plus précis que les généralistes (par exemple ChatGPT), bien que ces derniers donnent des résultats impressionnants, en particulier dans les versions les plus récentes. En ce qui concerne l’aptitude spécifique à la traduction médicale, il s’avère que les LLMs de petite taille, mais spécifiquement entraînés à cette tâche, restent pour l’instant supérieurs aux grands modèles [8]. La traduction fonctionne beaucoup moins bien si la langue souhaitée n’est pas souvent présente dans les données d’apprentissage.
Dans l’ensemble, l’application est actuellement limitée dans le domaine médical pour deux raisons : D’une part, les documents originaux ne peuvent pas être téléchargés et traduits en entier pour des raisons de protection des données, et d’autre part, le médecin traducteur reste responsable de l’exactitude du contenu, de sorte que les rapports critiques nécessitent toujours une traduction professionnelle. Si des LLM sont utilisés, il est recommandé de ne traduire que dans des langues pour lesquelles on peut au moins vérifier la plausibilité des traductions elles-mêmes.
Vignette de cas – Partie 4
L’hémicolectomie gauche programmée est réalisée sans complication. La tumeur primaire peut être entièrement retirée et les ganglions lymphatiques mésentériques prélevés se révèlent exempts de tumeur. La patiente se remet facilement de l’intervention en postopératoire et peut rentrer chez elle peu de temps après. Lors du suivi oncologique, elle ne présente aucune tumeur.
Le chirurgien viscéral qui opère utilise un LLM pour rédiger les notes de l’entretien d’entrée ainsi que les rapports d’opération et de sortie. Enfin, l’administration de l’hôpital qui réalise l’intervention utilise un LLM pour effectuer un pré-codage du cas selon Swiss-DRG à partir de la documentation disponible dans le système d’information clinique (SIC).
Rapports
La génération de nouveau texte est une discipline clé des LLM modernes. Celle-ci est généralement réussie avec une très bonne qualité sémantique. La qualité du contenu, en revanche, dépend fortement du contexte disponible. Plus le LLM dispose de détails, plus le texte généré sera précis. Dans la pratique clinique quotidienne, les rapports standardisés sont donc les plus adaptés à la génération automatique, par exemple les opérations et interventions standard ou les demandes de garantie de paiement. Les rapports plus complexes avec un contexte clinique important sont beaucoup moins efficaces. Pour cela, la génération devrait se faire directement à partir du système d’information de la clinique ou du cabinet médical et avoir accès à l’ensemble du contexte de traitement, ce qui – à l’heure actuelle – est encore insuffisant.
Lorsque des rapports sont générés avec des LLM, il incombe au médecin saisissant de vérifier la plausibilité du contenu généré et de le valider. Cela ne doit pas être sous-estimé, car les erreurs de contenu sont souvent plus difficiles à détecter en raison de la bonne qualité sémantique. La protection des données doit également être garantie à tout moment, en particulier lorsque des dossiers médicaux complets sont transmis au LLM en tant que contexte.
Notes de conversation
De plus en plus de produits arrivent sur le marché qui enregistrent via des microphones (par exemple de smartphones) la conversation avec les patients – même en dialecte ( !) – et la transcrivent en langage écrit à l’aide d’un LLM et, si nécessaire, la structurent et la résument pour le dossier médical. Ici aussi, les mêmes précautions et normes s’appliquent en matière d’hallucinations et de cadre médico-légal, et doivent être exigées des fabricants de logiciels. En outre, de nombreuses questions relatives à la revendication de ces fichiers audio sur le plan juridique n’ont pas encore été résolues. Dans tous les cas, toutes les parties concernées doivent être d’accord avec les enregistrements.
Codage/classification
La reconnaissance de modèles, même dans des données non structurées, est une capacité importante des LLM. En conséquence, l’idée que les LLM pourraient extraire des informations structurées des nombreuses données de texte libre non structurées qui sont générées quotidiennement dans la documentation clinique et rendre ainsi le traitement de ces données accessible, par exemple pour la facturation ou les statistiques, est très prometteuse. Cela est possible, mais le LLM doit être formé spécifiquement à cette fin. Les LLM “généralistes” habituels ne parviennent pas à coder/classer de manière fiable. Souvent, les différents catalogues et codes sont mélangés ou les codes sont tout simplement inventés (hallucinés).
Ce n’est qu’une question de temps avant que les LLM spécialisés ne soient intégrés dans les logiciels de codage. Mais même dans ce cas, les résultats devront toujours être validés par des codeurs humains, d’autant plus que les règles pures (par ex. SwissDRG) ne sont pas disponibles sous forme structurée, ce qui serait généralement très souhaitable.
Résumé
Comme toute innovation technologique, l’utilisation des LLM dans le quotidien de l’hôpital présente à la fois des opportunités et des risques. Ni une confiance aveugle, ni un rejet strict ne peuvent mener au but. Nous recommandons de se familiariser avec la nouvelle technologie et de limiter initialement son utilisation à une tâche simple dans un domaine où l’expertise personnelle est élevée. Cela permet de se faire rapidement une bonne idée des possibilités et des limites des LLM et d’étendre progressivement leur utilisation. Avant toute utilisation dans un contexte médical, il est toutefois impératif de toujours tenir compte des réglementations administratives, juridiques et éthiques en vigueur.
Dans l’ensemble, les nouvelles technologies et les nouvelles thérapies font partie du quotidien des médecins. Nous avons appris à les aborder avec une saine dose de scepticisme et à ne pas simplement les utiliser sur nos patients sans esprit critique. Ces principes scientifiques d’efficacité et d’adéquation doivent également s’appliquer à l’utilisation des LLM dans le quotidien clinique et nous devons les exiger des fournisseurs de ces outils, d’autant plus que les problèmes les plus fondamentaux des LLM – les hallucinations et la reproductibilité – ne sont pas encore résolus et le resteront peut-être. C’est dans ce contexte qu’il faudra également mener la discussion pour savoir si – comme cela se produit déjà nolens volens avec les systèmes de reconnaissance vocale purs – des sacrifices qualitatifs doivent être acceptés comme inévitables.
C’est dans ces conditions que nous pourrons, au cours des prochains mois et des prochaines années, utiliser cette nouvelle technologie dans le quotidien de l’hôpital, ce qui sera bénéfique pour nous et nos patients.
Messages Take-Home
- Les grands modèles linguistiques (LLM) génèrent de la langue, pas de la connaissance !
- Utilisés de manière ciblée, les LLM peuvent également apporter un soutien utile dans la pratique clinique quotidienne.
- Nous vous recommandons d’acquérir votre propre expérience afin de pouvoir évaluer les avantages et les risques de manière plus fiable.
- De nombreuses questions réglementaires, de protection des données et éthiques ne sont toujours pas résolues, en particulier dans le domaine médical. Tout ce qui est possible n’est pas forcément autorisé ! La responsabilité incombe en fin de compte au médecin qui utilise le produit.
| Grâce à |
| Les auteurs remercient Frederic Ehrler, Research & Development (R&D) Team Leader aux Hôpitaux Universitaires de Genève, et le reste du comité de la SSMI pour leur collaboration au projet initial MENTOR 2023 [1]. |
| Conflits d’intérêts |
| Les auteurs n’ont aucun conflit d’intérêt et en particulier aucun lien avec OpenAI et ChatGPT. Ces LLM ont été utilisés à titre d’exemple, car ils sont sans doute les plus connus des lecteurs. Les déclarations faites dans l’article s’appliquent pour l’essentiel à tous les LLM disponibles. Les auteurs sont tous deux membres du comité de la Société Suisse d’Informatique Médicale (SSIM), voir l’infobox. |
Littérature :
- Dürst L, et al.: ChatGPT im klinischen Alltag. Schweizerische Gesellschaft für Medizinische Informatik 2023; https://sgmi-ssim.org/wp-content/uploads/2023/10/Mentor-2023-ChatGPT-de.pdf.
- Coda-Forno J, et al : Inducing anxiety in large language models can induce bias ; doi : 10.48550/arXiv.2304.11111.
- Bicknell BT, et al.: ChatGPT-4 Omni Performance in USMLE Disciplines and Clinical Skills: Comparative Analysis. JMIR medical education 2024; 10: e63430; doi: 10.2196/63430.
- Hager P, et al.: Evaluation and mitigation of the limitations of large language models in clinical decision-making. Nature Medicine 2024; 30: 2613–2622; doi: 10.1038/s41591-024-03097-1.
- Deutsche Gesellschaft für Gastroenterologie, Verdauungs- und Stoffwechselkrankheiten e.V. (Société allemande de gastroentérologie, de digestion et de métabolisme), S3-Leitlinie Divertikelkrankheit/Divertikulitis (Lignes directrices S3 sur la diverticulite), version 2.1, 2021 ; https://register.awmf.org/de/leitlinien/detail/021-020.
- Thomo A: PubMed Retrieval with RAG Techniques. Studies in health technology and informatics 2024; 316: 652–653; doi: 10.3233/SHTI240498.
- Sorin V, et al.: Large Language Models and Empathy: Systematic Review. Journal of medical Internet 2024; 26: e52597; doi: 10.2196/52597.
- Keles B, et al.: LLMs-in-the-loop Part-1: Expert Small AI Models for Bio-Medical Text Translation; doi: 10.48550/arXiv.2407.12126.
- Promptingtipps. Digital Learning Hub Sek II, Zürich; https://dlh.zh.ch/home/genki/promptingtipps.
InFo NEUROLOGIE & PSYCHIATRIE 2025; 23(1): 6–11