Con la disponibilidad pública de ChatGPT 3.5 en otoño de 2022 a más tardar, la inteligencia artificial en el sentido de los grandes modelos lingüísticos (LLM ) está en boca de todos. Sin embargo, a menudo se olvida que esto no es más que el punto final provisional de décadas de desarrollo de la inteligencia artificial, que, a pesar de su gran potencial, sigue teniendo muchas limitaciones. Para los médicos en ejercicio, se plantea la cuestión de cómo puede utilizarse esta tecnología de forma sensata en la práctica clínica diaria, y cómo es mejor no utilizarla.
Puede realizar el examen CME en nuestra plataforma de aprendizaje después de revisar los materiales recomendados. Haga clic en el siguiente botón:
Con la disponibilidad pública de ChatGPT 3.5 en otoño de 2022 a más tardar, la inteligencia artificial en el sentido de los grandes modelos lingüísticos (LLM ) está en boca de todos. Sin embargo, a menudo se olvida que esto no es más que el punto final provisional de décadas de desarrollo de la inteligencia artificial, que, a pesar de su gran potencial, sigue teniendo muchas limitaciones.
Para los médicos en ejercicio, se plantea la cuestión de cómo puede utilizarse con sensatez esta fascinante tecnología en la práctica clínica diaria… y cómo no utilizarla. Con esta CME, queremos ofrecer aquí una ayuda concreta.
Viñeta de caso – Parte 1
Una paciente de 44 años acude a la consulta de su médico de cabecera con dolor en la parte inferior izquierda del abdomen. Los síntomas comenzaron hace unos días y ahora aumentan de forma constante. La paciente se encuentra en buen estado de salud general con constantes vitales estables. Presenta una sensibilidad mínima en la parte inferior izquierda del abdomen. No hay fiebre, los valores de inflamación están ligeramente elevados. Se sospecha de diverticulitis.
El joven colega de la consulta de medicina general está entusiasmado con las posibilidades de los grandes modelos lingüísticos y también le gustaría utilizarlos en su práctica clínica diaria.
Fundamentos técnicos [1]
Los grandes modelos lingüísticos (LLM) son una rama de la inteligencia artificial o del aprendizaje automático que se ocupa del procesamiento del lenguaje natural. Consisten en una red con docenas de capas y miles de millones o probablemente billones de conexiones (parámetros). Como esta estructura es similar a la de un cerebro biológico, se ha impuesto el término “red neuronal”.
La red se entrena con un amplio corpus de texto que suele estar disponible gratuitamente en Internet. No todos los fabricantes revelan el alcance exacto de los datos de entrenamiento. El entrenamiento es tanto automatizado (no supervisado) como dirigido por humanos (parcialmente supervisado) y consume mucho tiempo y recursos. La supervisión humana es necesaria para aumentar la calidad del aprendizaje y garantizar que no predomine el lenguaje negativo o agresivo. Al mismo tiempo, esta supervisión humana es también un área problemática, ya que los examinadores suelen estar mal pagados y posiblemente poco formados.
Durante el entrenamiento, los datos de entrenamiento se fragmentan (tokenizan ) en pequeños fragmentos como palabras o partes cortas de palabras y las conexiones entre ellos se ponderan en la red. Las conexiones frecuentes se refuerzan, las poco frecuentes se debilitan. Como resultado, la red desarrolla un conocimiento profundo de la estructura de la lengua en los datos de entrenamiento. Dependiendo de la configuración básica y de los datos de entrenamiento, una red puede especializarse para tareas específicas, por ejemplo, la traducción de idiomas. En la actualidad, las LLM son en su mayoría “generalistas” sin una especialización clara.
| Sociedad Suiza de Informática Médica (SGMI) |
| La Sociedad Suiza de Informática Médica (SGMI) promueve el estudio, el desarrollo y el uso de herramientas informáticas en el sector sanitario. Como organización neutral, el aspecto científico (eficacia, prueba de beneficios, conveniencia) es importante para nosotros en la difusión de las herramientas informáticas en la práctica clínica diaria (informática médica basada en pruebas). En consecuencia, la SGMI también se ve a sí misma como un socio prudente y fiable en el ámbito de la integración de sistemas, el diseño de procesos, la transferencia de datos y el uso en un ecosistema socio-técnico sanitario lo más orientado posible a las normas. |
| Como parte de sus actividades, la SGMI organiza anualmente en otoño la cumbre suiza de la e-salud. También publica periódicamente directrices sobre temas importantes de la informática médica (MENTOR). En septiembre de 2023, publicó un MENTOR sobre el tema “Los LLM en la práctica clínica diaria”, que sirvió de base para este artículo [1]. |
| > www.sgmi-ssim.ch |
Una vez finalizado el entrenamiento, la red y las conexiones ponderadas permanecen inalteradas. En este estado ya no es posible realizar cambios fundamentales en la red, pero aún puede fijarse el comportamiento de la respuesta. Por ejemplo, pueden fijarse la longitud de la respuesta, el estilo del lenguaje, las repeticiones de palabras y la aleatoriedad.
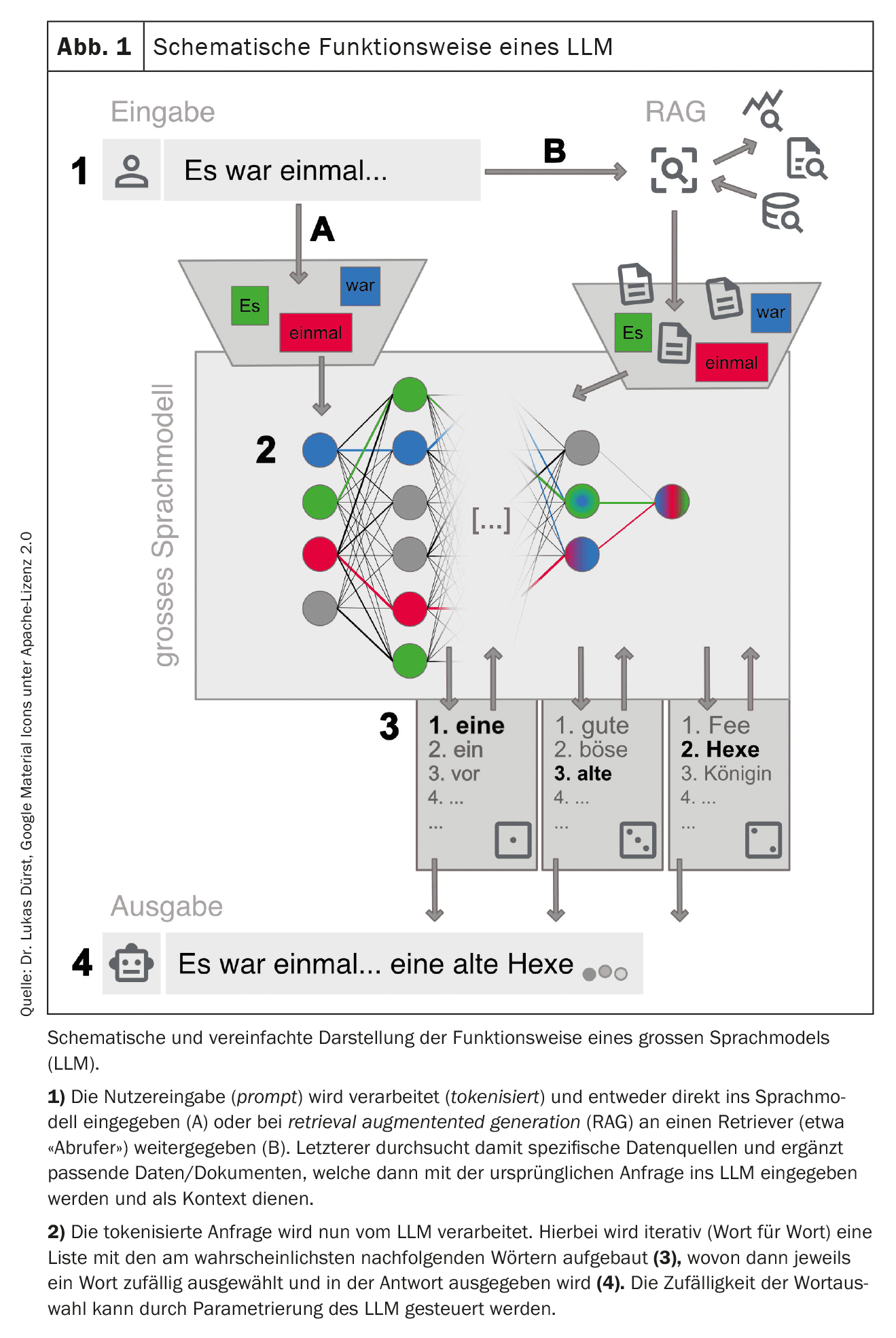
Ahora se puede interactuar con esta red totalmente entrenada. Esto suele hacerse a través de un chat en una página web o una aplicación para smartphone, pero también son posibles las conexiones técnicas directas a través de interfaces web (véanse ejemplos en la Tabla 1). La consulta (prompt) se prepara y se introduce en el LLM. A continuación, el LLM genera iterativamente una respuesta palabra por palabra (más exactamente: token por token). La siguiente palabra se selecciona de una lista de las siguientes palabras más probables. Esta selección es aleatoria hasta cierto punto para que la generación del texto parezca más creativa (“humana”). El grado de aleatoriedad puede ser fijado por los proveedores de la LLM o influido mediante una solicitud dirigida, pero en cualquier caso excluye la reproducibilidad completa de la respuesta (también porque no todas las solicitudes se responden con la misma instancia de las LLM disponibles).
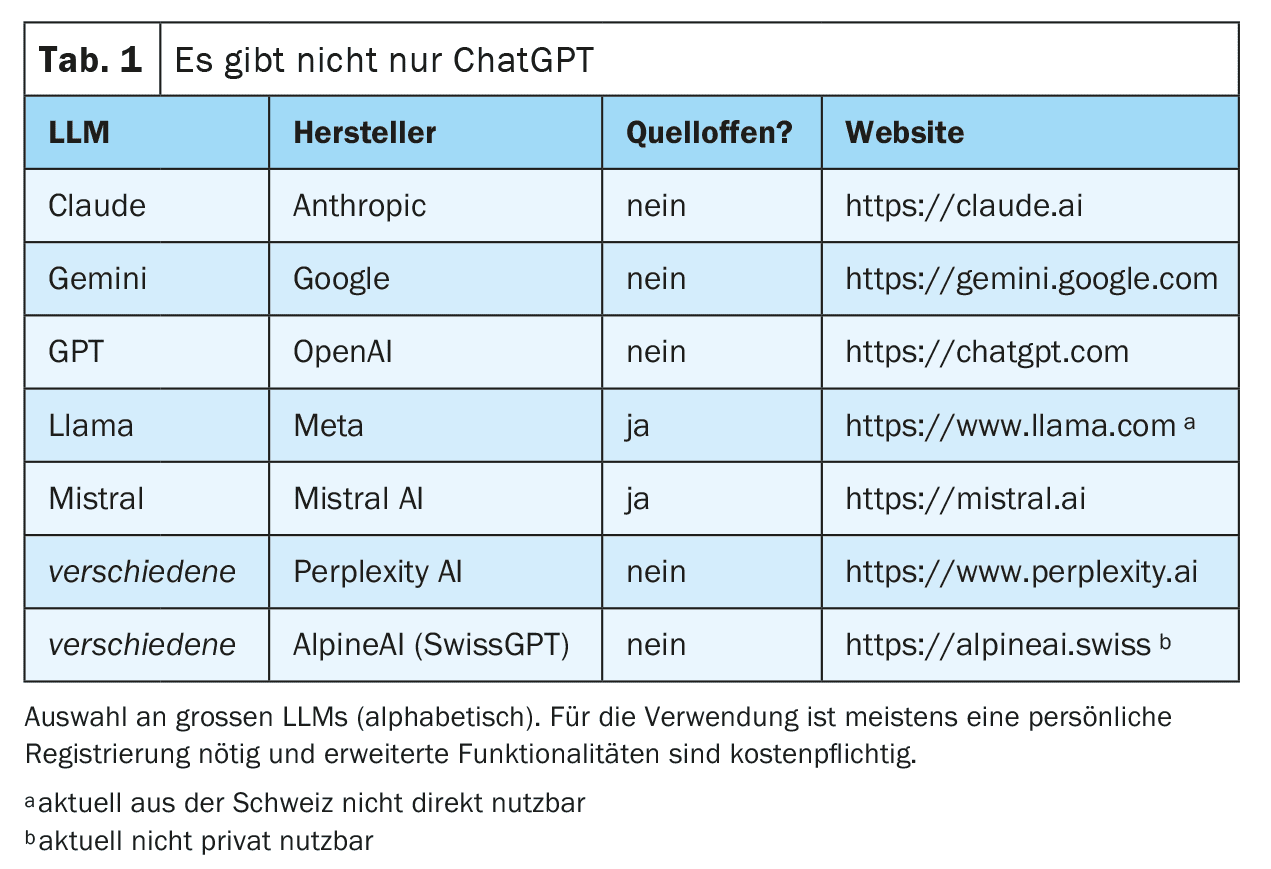
Para obtener los mejores resultados posibles, es importante seguir ciertas reglas al realizar una consulta y proporcionar un contexto lo más preciso posible. Este proceso -generar las mejores consultas posibles- se conoce como ingeniería de consultas (Tabla 2). Dependiendo del tipo de solicitud, los grandes proveedores también pueden utilizar diferentes LLM “especializados” en segundo plano. La figura 1 ofrece una visión simplificada del funcionamiento de un LLM.

Ventajas y desventajas
Los LLM modernos son sorprendentemente buenos imitando el habla humana. Esta capacidad es fundamentalmente independiente de la lengua de entrada utilizada, siempre que esta lengua esté disponible en cantidad suficiente en los datos de entrenamiento.
En los últimos LLM se dispone técnicamente de una gran parte de los conocimientos libres de Internet. Sin embargo, debido a su funcionamiento, no es posible que un LLM desarrolle sus propios conceptos y pensamientos (auténtica creatividad), sino que se limita a recombinar y reproducir los conocimientos disponibles del corpus de textos.
Recuerde: ¡los LLM generan lenguaje, no conocimiento!
Sin embargo, el modo de funcionamiento descrito también tiene algunas desventajas de las que los usuarios deben ser conscientes en todo momento. Por ejemplo, los LLM tienden a inventarse respuestas (alucinar) en lugar de admitir su ignorancia. Esto tiene que ver con el hecho de que en tales casos las palabras menos probables simplemente se añaden a la respuesta y ocurre especialmente cuando una respuesta se basa en datos de entrenamiento limitados, por ejemplo en el caso de una enfermedad rara. Aunque este riesgo puede reducirse mediante una buena configuración de los modelos, las alucinaciones no reconocidas siguen siendo un riesgo importante cuando se utilizan los LLM. Además, los LLM también pueden verse influidos negativamente por las indicaciones selectivas [2].
Debido a la falta de una comprensión global y a la selección aleatoria de la siguiente ficha, los LLM muestran problemas al tratar con la lógica y las matemáticas. Esto dificulta la reproducibilidad de una respuesta y, por tanto, su uso en la investigación y en un contexto médico-legal.
Otro problema de los LLM clásicos es la actualidad de los datos, ya que los conocimientos del LLM dejan de ampliarse una vez finalizado el entrenamiento. Los LLM modernos ofrecen la opción de proporcionar un contexto adicional actualizado, por ejemplo, a partir de una búsqueda bibliográfica (generación aumentada por recuperación, RAG), lo que mitiga el problema y mejora la fiabilidad de la respuesta. En este contexto, el LLM puede incluso proporcionar información fiable sobre la fuente, lo que de otro modo no sería posible. Por lo tanto, el usuario debe ser consciente de con qué variante de LLM se está comunicando.
Por último, hay toda una serie de aspectos legales, normativos y éticos, como la protección de datos, la responsabilidad y los derechos de autor, que aún no han sido suficientemente aclarados por la sociedad en su conjunto y que son fuente de gran incertidumbre para el uso correcto de los LLM, sobre todo en la práctica médica diaria. Los sistemas con autonomía nacional (sobre todo en el ámbito de la protección de datos y la legislación suiza) pueden ofrecer aquí un remedio parcial. Health Info Net AG (HIN) – tradicionalmente asociada a la seguridad en el intercambio de datos en el sistema sanitario suizo – parece estar entablando aquí una colaboración con SwissGPT. Sin embargo, aún no es posible evaluar su penetración y aceptación en el mercado.
Recuerde: ¡No todo lo que funciona está permitido!
Ámbitos de aplicación
Viñeta de caso – Parte 2
Para estar más segura, la joven colega, todavía algo inexperta, consulta a un LLM, que también menciona la diverticulitis como diagnóstico diferencial más probable. El LLM también menciona la torsión o quiste ovárico y los cálculos renales como posibles diagnósticos diferenciales. El examen ecográfico focalizado revela hallazgos compatibles con diverticulitis. No hay indicios de un curso localmente complicado.
El LLM sugiere una terapia antibiótica ambulatoria y una colonoscopia de seguimiento al cabo de unas semanas. El colega y la paciente aceptan esta propuesta de tratamiento. La paciente se recupera según lo previsto en unos días.
Realización de diagnósticos y razonamiento diagnóstico
El hecho de que los amplios conocimientos del Dr. ChatGPT apoyen a los médicos en el proceso de diagnóstico y en las decisiones de tratamiento parece una aplicación obvia.
Al fin y al cabo, los LLM modernos aprueban el examen estatal de medicina de EE.UU. (USMLE) con altas puntuaciones de más del 90% con los últimos LLM [3]. Esto no resulta sorprendente si se examina más detenidamente, ya que estas viñetas de casos están muy estructuradas y resumen toda la información necesaria para realizar un diagnóstico o responder a la pregunta. Además, es probable que muchas de las preguntas ya estuvieran presentes en el conjunto de datos de entrenamiento de los LLM.
Resulta más interesante cuando los LLM tienen que adquirir información sobre los propios pacientes en un proceso de diagnóstico. En este caso, los resultados son mucho menos impresionantes [4]. Esto tampoco es realmente sorprendente, ya que una gran cantidad de información aún no está disponible o no lo está en formato digital, especialmente en la fase inicial de un diagnóstico, pero un LLM necesita la información más detallada posible para obtener los mejores resultados. Además, su debilidad fundamental para tratar con números les dificulta la interpretación de las constantes vitales y los valores de laboratorio.
Debido a su modo de funcionamiento, un LLM resulta ahora adecuado principalmente como medio para reconocer posibles patrones a partir de un conjunto de información proporcionada que aún puede permanecer oculta para el médico, es decir, principalmente para el diagnóstico diferencial.
Su uso generalizado en la práctica clínica diaria para el apoyo a la toma de decisiones también se ve limitado por los requisitos aplicables en materia de responsabilidad, protección de datos y certificación como producto médico.
Recomendaciones de tratamiento y búsqueda bibliográfica
Dado que la mayoría de las directrices de tratamiento están disponibles gratuitamente en Internet, no es de extrañar que los LLM también puedan hacer recomendaciones de tratamiento acordes con las directrices. El principal problema aquí es la limitación temporal de los datos de entrenamiento. Las directrices y los resultados de estudios más recientes no suelen estar entrenados en el LLM. En el caso concreto del ejemplo, obviamente falta la opción de tratamiento más reciente “vigilar y esperar” para la diverticulitis no complicada y los factores de riesgo ausentes [5]. Las obras de referencia y las bases de datos bibliográficas de alta calidad y con mantenimiento editorial siguen teniendo la ventaja de estar actualizadas.
Otro factor que complica la situación es la incapacidad de los LLM clásicos para citar la fuente exacta. Siempre quedará poco claro a qué versiones de directrices se refiere el LLM y si ha mezclado directrices diferentes. En este caso, las GAR mencionadas anteriormente pueden proporcionar resultados mucho más fiables. Si se utilizan para buscar en Pubmed, por ejemplo, la relevancia de los resultados de la búsqueda puede mejorar significativamente [6]. Otra ventaja de este método es que los estudios encontrados también pueden añadirse al LLM como contexto y todas sus funcionalidades, como resumir, traducir y analizar, pueden utilizarse después en el trabajo original.
Los LLM modernos también ofrecen la opción de proporcionar manualmente un contexto adicional durante la investigación. Por ejemplo, se puede adjuntar un estudio encontrado y así resumirlo y analizarlo rápidamente. Sin embargo, hay que tener en cuenta que existe un límite en cuanto a lo “grande” que puede ser una consulta, especialmente con las versiones gratuitas de los LLM. Por tanto, debe comprobarse en cada caso el tamaño real posible de la entrada o del contexto (límite de contexto). Además, estos resúmenes no están exentos de alucinaciones.
Viñeta de caso – Parte 3
Por desgracia, la colonoscopia de seguimiento realizada unas semanas más tarde reveló un diagnóstico de adenocarcinoma de colon sigmoide sin pruebas de imagen de metástasis local o a distancia (estadio I de la UICC).
El colega de la consulta no está seguro de cuál es la mejor manera de comunicar los resultados desfavorables a la joven madre. Recurre a un LLM para prepararse para la difícil conversación.
Durante la consulta, recurre a un LLM para explicar los hechos médicos a la paciente de forma sencilla y en su portugués nativo. A petición de la paciente, también hace traducir su breve informe médico al portugués por un LLM.
Gestión de la conversación
A primera vista, parece contraintuitivo pedir consejo a una máquina en lo que se supone que es la “disciplina parangonable” humana de la comunicación. Sin embargo, dado que la función principal de los LLM es imitar el habla humana lo más fielmente posible, este planteamiento ya no parece tan descabellado a segunda vista. Así, algunos estudios ya han demostrado que los LLM modernos son capaces de dar respuestas que contienen elementos de “empatía”, que luego también son interpretadas como “empáticas” por el interlocutor humano [7]. Con las indicaciones adecuadas, se pueden reproducir diversas técnicas para dirigir la conversación y variantes de la misma, lo que puede dar una confianza adicional sobre todo a los médicos inexpertos. Por supuesto, esto no libera al médico de la comunicación empática y directa final con el paciente.
Educación del paciente
Cuando se les instruye adecuadamente, los LLM son muy buenos a la hora de presentar contenidos médicos especializados en un lenguaje fácil de entender. Por lo tanto, sin duda merece la pena intentar utilizar herramientas basadas en los LLM en la educación del paciente. Sin embargo, es importante que el paciente siga estando supervisado de cerca por un médico. El deber del médico de proporcionar información no puede delegarse en un LLM.
Traducción de
Los LLM pueden traducir muy bien entre distintos idiomas. Esto funciona no sólo con las lenguas naturales, sino también con construcciones lingüísticas artificiales como los lenguajes de programación. Los LLM que han sido entrenados específicamente para traducciones (por ejemplo, deepl.com) probablemente siguen siendo superiores a los generalistas (por ejemplo, ChatGPT) en cuanto a precisión, aunque estos últimos también ofrecen resultados impresionantes, sobre todo en las últimas versiones. En cuanto a la idoneidad específica para las traducciones médicas, está claro que los LLM pequeños que han sido entrenados específicamente para esta tarea siguen siendo actualmente superiores a los modelos grandes [8]. La traducción funciona significativamente peor si la lengua deseada rara vez estaba presente en los datos de entrenamiento.
En general, la aplicación está actualmente limitada en el ámbito médico por dos razones: Por un lado, los documentos originales completos no pueden cargarse y traducirse por cuestiones de protección de datos; por otro, el médico traductor sigue siendo el responsable último de la exactitud del contenido, lo que significa que sigue siendo necesaria una traducción profesional para los informes críticos. Si se utilizan LLM, es aconsejable traducir únicamente a idiomas en los que al menos se pueda comprobar la verosimilitud de las propias traducciones.
Viñeta de caso – Parte 4
La hemicolectomía izquierda prevista se realiza sin complicaciones. El tumor primario puede extirparse por completo y los ganglios linfáticos mesentéricos extirpados están libres de tumor. En el postoperatorio, la paciente se recupera de la operación sin problemas y puede volver a casa al poco tiempo. Permanece libre de tumor en el postoperatorio oncológico.
El cirujano visceral que realiza la operación utiliza un LLM para crear las notas de la consulta de ingreso y los informes de la operación y el alta. Por último, la administración del hospital que realiza la operación utiliza un LLM para precodificar el caso según el Swiss-DRG a partir de la documentación disponible en el sistema de información hospitalaria (HIS).
Informar
La generación de nuevos textos es una disciplina central de los LLM modernos. Normalmente se consigue con una calidad semántica muy buena. La calidad del contenido, por otra parte, depende en gran medida del contexto disponible. Cuantos más detalles tenga a su disposición el LLM, más preciso será el texto generado. Por ello, en la práctica clínica diaria, los informes estandarizados son principalmente adecuados para la generación automática, por ejemplo, operaciones estándar, intervenciones o solicitudes de reembolso. Los informes más complejos con mucho contexto clínico tienen mucho menos éxito, ya que tendrían que generarse directamente desde el sistema de información del hospital o la consulta y tener acceso a todo el contexto del tratamiento, lo que -tal y como están las cosas hoy en día- aún no está suficientemente logrado.
Si los informes se generan con LLM, es responsabilidad del médico registrador comprobar la plausibilidad del contenido generado y aprobarlo. Esto no debe subestimarse, ya que los errores en el contenido suelen ser más difíciles de detectar debido a la buena calidad semántica. La protección de datos también debe garantizarse en todo momento, especialmente si se proporcionan historiales médicos completos al LLM como contexto.
Notas de conversación
Cada vez más, también salen al mercado productos que utilizan micrófonos (por ejemplo, en los teléfonos inteligentes) para grabar las conversaciones con los pacientes -incluso en dialecto (¡!)- y transcribirlas al lenguaje escrito mediante un LLM y, si es necesario, estructurarlas y resumirlas para la historia clínica. También en este caso se aplican las mismas medidas y normas de precaución en cuanto a las alucinaciones y las condiciones del marco médico-legal, que deben ser exigidas en consecuencia por los fabricantes de software. Además, aún no se han aclarado muchas cuestiones relativas a los aspectos legales de la solicitud de estos archivos de audio. En cualquier caso, todas las partes implicadas deben estar de acuerdo con las grabaciones.
Codificación/clasificación
Reconocer patrones incluso en datos no estructurados es una capacidad importante de los LLM. La idea de que los LLM puedan derivar información estructurada de la gran cantidad de datos de texto libre no estructurados que se generan a diario en la documentación clínica y hacer así accesible el procesamiento de estos datos para la facturación o la estadística, por ejemplo, es correspondientemente prometedora. Esto es posible, pero el LLM debe recibir una formación específica para ello. Los “LLM generalistas” habituales son mucho menos fiables cuando se trata de codificación/clasificación. A menudo se mezclan diferentes catálogos y códigos o simplemente se inventan códigos (alucinan).
Sin embargo, es probable que sólo sea cuestión de tiempo que las LLM debidamente especializadas encuentren su camino en el software de codificación. Pero también en este caso, por el momento los resultados tendrán que ser comprobados en cuanto a su plausibilidad y aprobados por codificadores humanos, sobre todo porque el conjunto puro de reglas (por ejemplo, SwissDRG) no está disponible de forma estructurada, lo que en general sería muy deseable.
Resumen
Como cualquier innovación tecnológica, el uso de los LLM en la práctica clínica diaria ofrece tanto oportunidades como riesgos. Ni la confianza ciega ni el rechazo estricto son convenientes. Le recomendamos que se familiarice con la nueva tecnología y que limite inicialmente su uso a una tarea sencilla en un área en la que tenga un alto nivel de experiencia. De este modo, podrá hacerse rápidamente una idea de las posibilidades y limitaciones de las LLM y ampliar poco a poco su uso a partir de ahí. No obstante, antes de cualquier uso en un contexto médico, siempre hay que tener en cuenta la normativa administrativa, jurídica y ética aplicable.
En general, las nuevas tecnologías y terapias forman parte de la vida cotidiana de los médicos. Hemos aprendido a abordarlas con una saludable dosis de escepticismo y a no utilizarlas sin más y de forma acrítica con nuestros pacientes. También debemos aplicar estos principios científicos de eficacia e idoneidad cuando utilicemos las LLM en la práctica clínica diaria y exigírselos a los proveedores de estas herramientas, sobre todo porque los problemas más fundamentales de las LLM -las alucinaciones y la reproducibilidad- siguen sin resolverse y quizá sigan así. En este contexto, también habrá que debatir si -como ya ocurre con los sistemas puros de reconocimiento del habla- deben aceptarse como inevitables los compromisos cualitativos.
En estas condiciones, podemos conseguir en los próximos meses y años utilizar esta nueva tecnología en la práctica clínica diaria en beneficio nuestro y de nuestros pacientes.
Mensajes para llevar a casa
- Los grandes modelos lingüísticos (LLM) generan lenguaje, ¡no conocimiento!
- Cuando se utilizan de forma selectiva, los LLM también pueden proporcionar un apoyo útil en la práctica clínica diaria.
- Le recomendamos que adquiera su propia experiencia para poder evaluar los beneficios y los riesgos con mayor fiabilidad.
- Quedan por resolver muchas cuestiones normativas, de protección de datos y éticas, sobre todo en el sector médico. ¡No todo lo que funciona está permitido! En última instancia, la responsabilidad recae en el médico que utiliza el dispositivo.
| Gracias a |
| Los autores desean agradecer a Frederic Ehrler, Jefe del Equipo de Investigación y Desarrollo (I+D) del Hospital Universitario de Ginebra, y al resto de la Junta de SGMI su colaboración en el MENTOR 2023 original [1]. |
| Conflictos de intereses |
| Los autores no tienen ningún conflicto de intereses y, en particular, ninguna relación con OpenAI y ChatGPT. Estos LLM se utilizaron como ejemplo, ya que es probable que sean los más familiares para los lectores. Las afirmaciones del artículo se aplican esencialmente a todos los LLM disponibles. Ambos autores forman parte de la junta directiva de la Sociedad Suiza de Informática Médica (SGMI), véase el recuadro informativo. |
Literatura:
- Dürst L, et al.: ChatGPT im klinischen Alltag. Schweizerische Gesellschaft für Medizinische Informatik 2023; https://sgmi-ssim.org/wp-content/uploads/2023/10/Mentor-2023-ChatGPT-de.pdf.
- Coda-Forno J, et al.: Inducing anxiety in large language models can induce bias; doi: 10.48550/arXiv.2304.11111.
- Bicknell BT, et al.: ChatGPT-4 Omni Performance in USMLE Disciplines and Clinical Skills: Comparative Analysis. JMIR medical education 2024; 10: e63430; doi: 10.2196/63430.
- Hager P, et al.: Evaluation and mitigation of the limitations of large language models in clinical decision-making. Nature Medicine 2024; 30: 2613–2622; doi: 10.1038/s41591-024-03097-1.
- Deutsche Gesellschaft für Gastroenterologie, Verdauungs- und Stoffwechselkrankheiten e.V., S3-Leitlinie Divertikelkrankheit/Divertikulitis, Version 2.1, 2021; https://register.awmf.org/de/leitlinien/detail/021-020.
- Thomo A: PubMed Retrieval with RAG Techniques. Studies in health technology and informatics 2024; 316: 652–653; doi: 10.3233/SHTI240498.
- Sorin V, et al.: Large Language Models and Empathy: Systematic Review. Journal of medical Internet 2024; 26: e52597; doi: 10.2196/52597.
- Keles B, et al.: LLMs-in-the-loop Part-1: Expert Small AI Models for Bio-Medical Text Translation; doi: 10.48550/arXiv.2407.12126.
- Promptingtipps. Digital Learning Hub Sek II, Zürich; https://dlh.zh.ch/home/genki/promptingtipps.
InFo NEUROLOGIE & PSYCHIATRIE 2025; 23(1): 6–11