Con la disponibilità pubblica di ChatGPT 3.5 al più tardi nell’autunno del 2022, l’intelligenza artificiale nel senso di grandi modelli linguistici (LLM ) è sulla bocca di tutti. Tuttavia, spesso si dimentica che questo è solo il punto finale provvisorio di decenni di sviluppo dell’intelligenza artificiale, che, nonostante il suo grande potenziale, ha ancora molti limiti. Per i medici praticanti, si pone la questione di come questa tecnologia possa essere utilizzata in modo sensato nella pratica clinica quotidiana – e di come sia meglio non utilizzarla.
Può sostenere il test ECM nella nostra piattaforma di apprendimento dopo aver esaminato i materiali consigliati. Clicchi sul seguente pulsante:
Con la disponibilità pubblica di ChatGPT 3.5 al più tardi nell’autunno del 2022, l’intelligenza artificiale nel senso di grandi modelli linguistici (LLM ) è sulla bocca di tutti. Tuttavia, spesso si dimentica che questo è solo il punto finale provvisorio di decenni di sviluppo dell’intelligenza artificiale, che, nonostante il suo grande potenziale, ha ancora molti limiti.
Per i medici praticanti, si pone la questione di come questa affascinante tecnologia possa essere utilizzata in modo sensato nella pratica clinica quotidiana – e come non dovrebbe essere utilizzata. Con questo ECM, vogliamo offrire un aiuto concreto.
Caso vignetta – Parte 1
Una paziente di 44 anni si presenta al medico di famiglia con un dolore all’addome inferiore sinistro. I sintomi sono iniziati qualche giorno fa e ora sono in costante aumento. La paziente è in buona salute generale con segni vitali stabili. C’è un’indolenzimento nella parte inferiore sinistra dell’addome, con una minima tensione. Non c’è febbre, valori di infiammazione leggermente elevati. Si sospetta una diverticolite.
Il giovane collega dello studio medico di base è entusiasta delle possibilità dei modelli linguistici di grandi dimensioni e vorrebbe utilizzarli anche nella sua pratica clinica quotidiana.
Nozioni tecniche di base [1]
I grandi modelli linguistici (LLM) sono un ramo dell’intelligenza artificiale o dell’apprendimento automatico che si occupa dell’elaborazione del linguaggio naturale. Sono costituiti da una rete con decine di strati e da miliardi a probabilmente trilioni di connessioni (parametri). Poiché questa struttura è simile a un cervello biologico, si è affermato il termine “rete neurale”.
La rete viene addestrata su un ampio corpus di testo che di solito è disponibile gratuitamente su Internet. Non tutti i produttori rivelano l’esatta portata dei dati di addestramento. L’addestramento è sia automatizzato (non supervisionato) che guidato dall’uomo (parzialmente supervisionato) e richiede molto tempo e risorse. La supervisione umana è necessaria per aumentare la qualità dell’apprendimento e per garantire che non prevalga un linguaggio negativo o aggressivo. Allo stesso tempo, questa supervisione umana è anche un’area problematica, in quanto gli esaminatori sono spesso sottopagati e forse poco formati.
Durante l’addestramento, i dati di addestramento vengono frammentati (tokenizzati ) in piccoli frammenti, come parole o brevi parti di parole, e le connessioni tra loro vengono ponderate nella rete. Le connessioni frequenti vengono rafforzate, quelle rare vengono indebolite. Di conseguenza, la rete sviluppa una conoscenza approfondita della struttura della lingua nei dati di formazione. A seconda delle impostazioni di base e dei dati di addestramento, una rete può essere specializzata per compiti specifici, ad esempio la traduzione linguistica. Gli LLM attualmente in esame sono per lo più ‘generalisti’, senza una chiara specializzazione.
| Società svizzera di informatica medica (SGMI) |
| La Società Svizzera di Informatica Medica (SGMI) promuove lo studio, lo sviluppo e l’utilizzo degli strumenti informatici nel settore sanitario. In qualità di organizzazione neutrale, l’aspetto scientifico (efficacia, prova del beneficio, convenienza) è importante per noi nella diffusione degli strumenti informatici nella pratica clinica quotidiana (informatica medica basata sull’evidenza). Di conseguenza, l’SGMI si considera anche un partner prudente e affidabile nell’ambito dell’integrazione dei sistemi, della progettazione dei processi, del trasferimento e dell’utilizzo dei dati in un ecosistema sanitario socio-tecnico il più possibile orientato agli standard. |
| Nell’ambito delle sue attività, la SGMI organizza l’annuale Swiss ehealthsummit in autunno. Inoltre, pubblica a intervalli regolari delle linee guida su temi importanti dell’informatica medica (MENTOR). Nel settembre 2023, ha pubblicato un MENTOR sul tema “I LLM nella pratica clinica quotidiana”, che è servito come base per questo articolo [1]. |
| > www.sgmi-ssim.ch |
Una volta completata la formazione, la rete e le connessioni ponderate rimangono invariate. In questo stato non è più possibile apportare modifiche fondamentali alla rete, ma è ancora possibile impostare il comportamento della risposta. Ad esempio, è possibile impostare la lunghezza della risposta, lo stile linguistico, le ripetizioni di parole e la casualità.
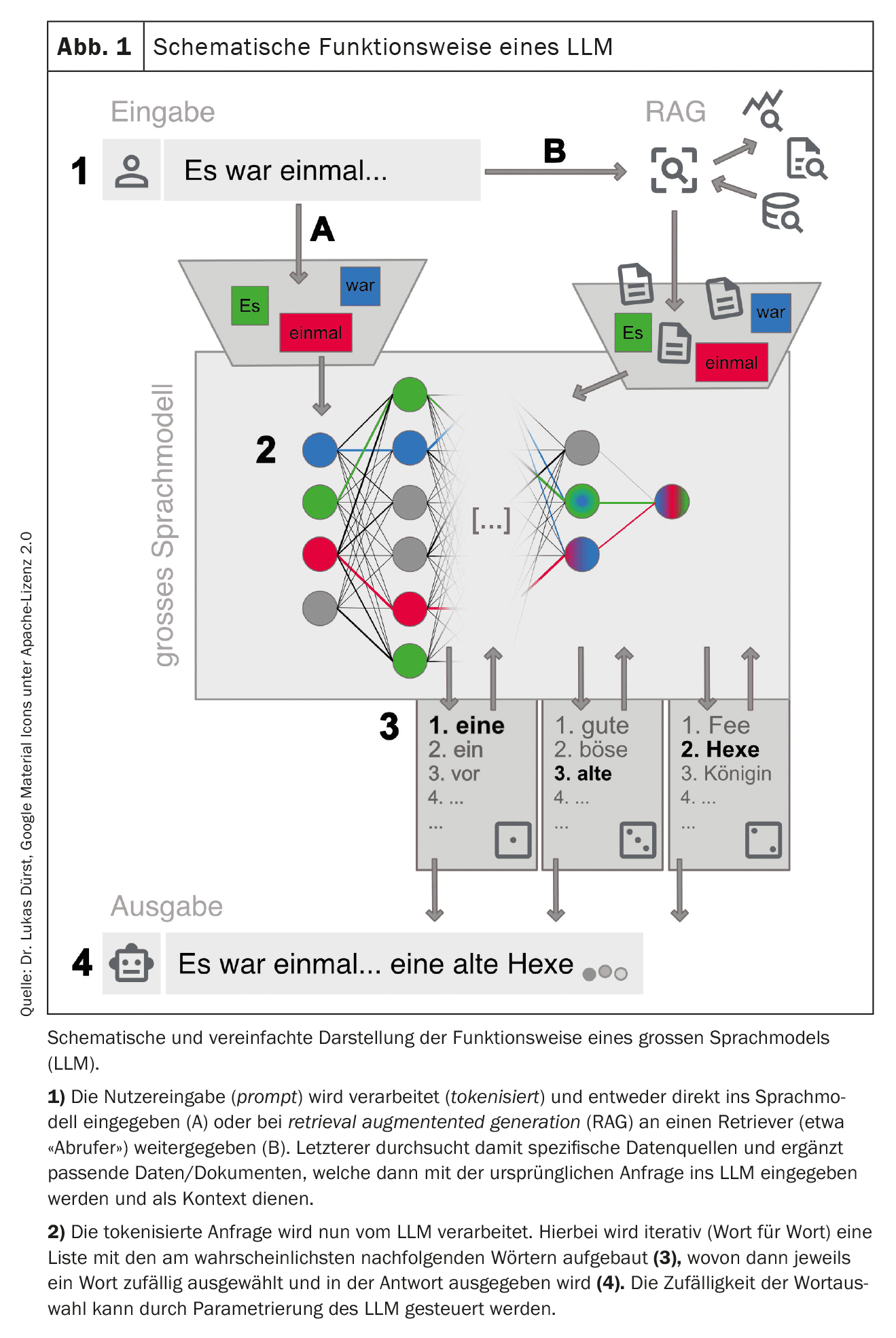
A questo punto è possibile interagire con questa rete addestrata. Ciò avviene spesso tramite una chat su un sito web o un’applicazione per smartphone, ma sono possibili anche connessioni tecniche dirette tramite interfacce web (vedere la Tabella 1 per gli esempi ). La richiesta (prompt) viene preparata e inserita nell’LLM. L’LLM genera poi iterativamente una risposta parola per parola (più precisamente: token per token). La parola successiva viene selezionata da un elenco di parole successive più probabili. Questa selezione è casuale in una certa misura, per far apparire la generazione del testo più creativa (“umana”). Il grado di casualità può essere impostato dai fornitori dell’LLM o influenzato tramite una richiesta mirata, ma in ogni caso esclude la riproducibilità completa della risposta (anche perché non tutte le richieste vengono risposte con la stessa istanza degli LLM disponibili).
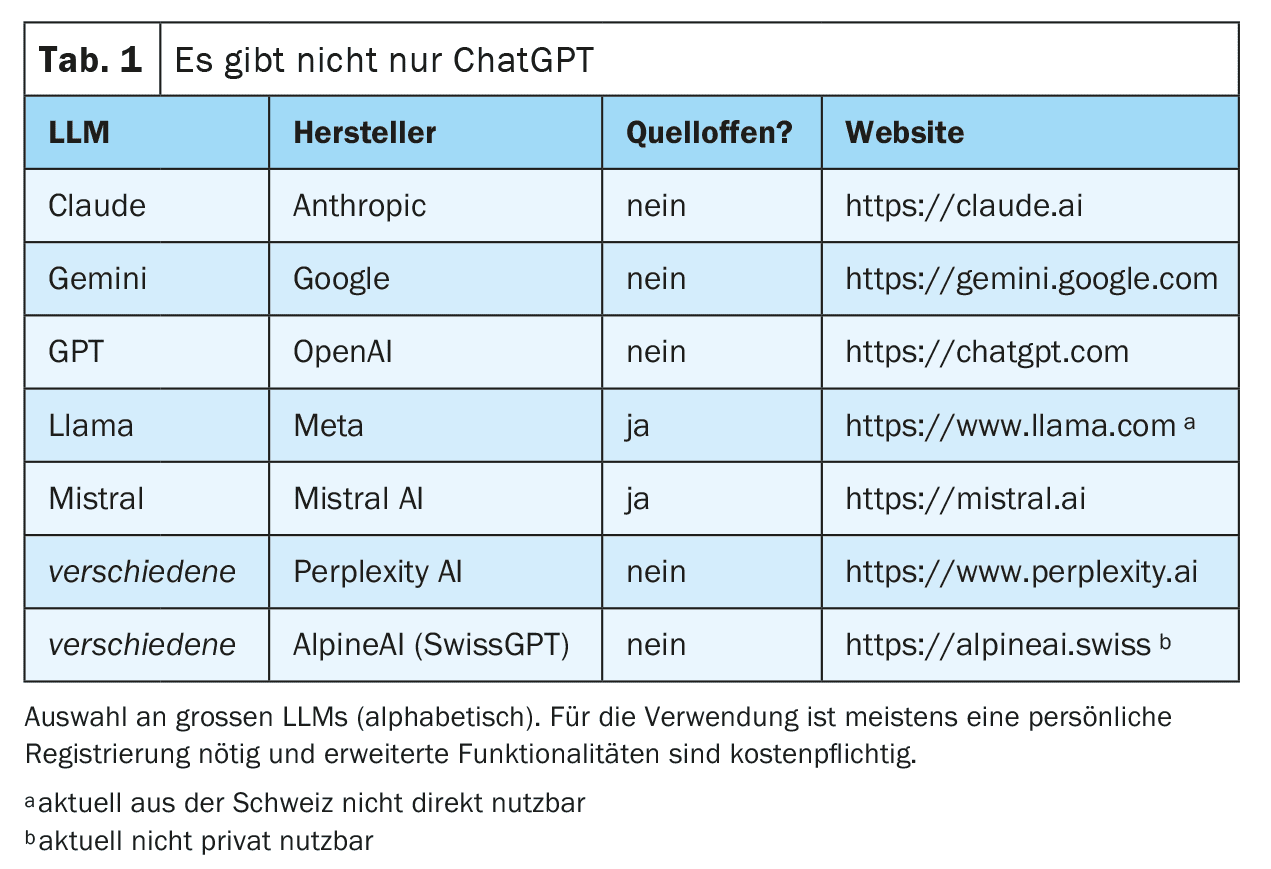
Per ottenere i migliori risultati possibili, è importante seguire alcune regole quando si effettua una query e fornire un contesto il più preciso possibile. Questo processo – generare le migliori query possibili – è noto come prompt engineering (Tabella 2). A seconda del tipo di richiesta, i grandi provider possono anche utilizzare diversi LLM ‘specializzati’ in background. La Figura 1 fornisce una panoramica semplificata del funzionamento di un LLM.

Vantaggi e svantaggi
I moderni LLM sono sorprendentemente bravi a imitare il parlato umano. Questa capacità è fondamentalmente indipendente dalla lingua di ingresso utilizzata, purché questa lingua sia disponibile in quantità sufficiente nei dati di formazione.
Negli ultimi LLM, è tecnicamente disponibile gran parte della conoscenza libera da Internet. Tuttavia, a causa del suo funzionamento, non è possibile per un LLM sviluppare concetti e pensieri propri (creatività autentica), ma solo ricombinare e riprodurre le conoscenze disponibili dal corpus testuale.
Ricorda: i LLM generano linguaggio, non conoscenza!
Tuttavia, la modalità di funzionamento descritta presenta anche alcuni svantaggi di cui gli utenti devono essere sempre consapevoli. Ad esempio, i LLM tendono a inventare le risposte (allucinazioni) invece di ammettere l’ignoranza. Questo ha a che fare con il fatto che in questi casi le parole meno probabili vengono semplicemente aggiunte alla risposta e accade soprattutto quando una risposta si basa su dati di formazione limitati, ad esempio nel caso di una malattia rara. Sebbene questo rischio possa essere ridotto da una buona configurazione dei modelli, le allucinazioni non riconosciute rimangono un rischio importante quando si utilizzano gli LLM. Inoltre, gli LLM possono essere influenzati negativamente da sollecitazioni mirate [2].
A causa della mancanza di una comprensione globale e della selezione casuale del token successivo, i LLM mostrano problemi nel trattare la logica e la matematica. Ciò rende più difficile la riproducibilità di una risposta e quindi il suo utilizzo nella ricerca e in un contesto medico-legale.
Un altro problema dei LLM classici è l’attualità dei dati, in quanto la conoscenza del LLM non viene più ampliata una volta completata la formazione. I moderni LLM offrono la possibilità di fornire un contesto aggiuntivo e aggiornato, ad esempio da una ricerca in letteratura (retrieval augmented generation, R AG), che mitiga il problema e migliora l’affidabilità della risposta. In questo contesto, l’LLM può persino fornire informazioni affidabili sulla fonte, che altrimenti non è possibile. L’utente deve quindi essere consapevole della variante di LLM con cui sta comunicando.
Infine, ci sono tutta una serie di aspetti legali, normativi ed etici, come la protezione dei dati, la responsabilità e il diritto d’autore, che non sono ancora stati sufficientemente chiariti dalla società nel suo complesso e che sono fonte di grande incertezza per l’uso corretto dei LLM, in particolare nella pratica medica quotidiana. I sistemi con autonomia nazionale (in particolare nell’ambito della protezione dei dati e della legislazione svizzera) possono offrire un rimedio parziale. Health Info Net AG (HIN) – tradizionalmente associata alla sicurezza nello scambio di dati nel sistema sanitario svizzero – sembra che stia per avviare una partnership con SwissGPT in questo ambito. Tuttavia, non è ancora possibile valutare la penetrazione e l’accettazione del mercato.
Si ricordi: non tutto ciò che funziona è permesso!
Aree di applicazione
Caso di vignetta – Parte 2
Per sicurezza, la giovane collega, ancora un po’ inesperta, consulta un medico di base, che indica anche la diverticolite come la diagnosi differenziale più probabile. Il medico legale ha anche menzionato la torsione o la cisti ovarica e i calcoli renali come possibili diagnosi differenziali. L’esame ecografico focalizzato rivela risultati coerenti con la diverticolite. Non ci sono indicazioni di un decorso localmente complicato.
Il medico legale suggerisce una terapia antibiotica ambulatoriale e una colonscopia di controllo dopo qualche settimana. Il collega e il paziente accettano questa proposta di trattamento. Il paziente si riprende come previsto entro pochi giorni.
Fare diagnosi e ragionamento diagnostico
Il fatto che l’ampia conoscenza del Dr ChatGPT supporti i medici nel processo diagnostico e nelle decisioni terapeutiche sembra essere un’applicazione ovvia.
Dopo tutto, i moderni LLM superano l’esame di stato di medicina degli Stati Uniti (USMLE) con punteggi elevati, superiori al 90% con gli ultimi LLM [3]. Questo non sorprende a un’analisi più attenta, poiché queste vignette di casi sono molto strutturate e riassumono tutte le informazioni necessarie per fare una diagnosi o rispondere alla domanda. Inoltre, molte delle domande erano probabilmente già presenti nel set di dati di formazione degli LLM.
Diventa più interessante quando gli LLM devono acquisire informazioni sui pazienti stessi in un processo diagnostico. In questo caso, i risultati sono molto meno impressionanti [4]. Anche questo non è davvero sorprendente, poiché molte informazioni non sono ancora disponibili o non sono disponibili in forma digitale, soprattutto nella fase iniziale di una diagnosi, ma un LLM ha bisogno di informazioni più dettagliate possibili per ottenere i migliori risultati. Inoltre, la loro debolezza fondamentale nel trattare i numeri rende difficile l’interpretazione dei segni vitali e dei valori di laboratorio.
Per il suo funzionamento, un LLM è ora adatto soprattutto come mezzo per riconoscere possibili modelli da un insieme di informazioni fornite che possono ancora rimanere nascoste al medico, cioè principalmente per la diagnosi differenziale.
L’uso diffuso nella pratica clinica quotidiana per il supporto decisionale è limitato anche dai requisiti applicabili in materia di responsabilità, protezione dei dati e certificazione come prodotto medico.
Raccomandazioni di trattamento e ricerca della letteratura
Poiché la maggior parte delle linee guida terapeutiche sono liberamente disponibili online, non sorprende che i LLM possano anche formulare raccomandazioni terapeutiche conformi alle linee guida. Il problema principale è la limitazione temporale dei dati di formazione. Le linee guida e i risultati degli studi più recenti spesso non vengono addestrati nell’LLM. Nel caso specifico dell’esempio, manca ovviamente l’opzione di trattamento più recente “watch & wait” per la diverticolite non complicata e i fattori di rischio mancanti [5]. Le opere di riferimento e le banche dati della letteratura di alta qualità e curate editorialmente hanno ancora il vantaggio di essere aggiornate.
Un altro fattore di complicazione è l’incapacità degli LLM classici di citare la fonte esatta. Rimarrà sempre poco chiaro a quali versioni di linee guida fa riferimento l’LLM e se ha mescolato linee guida diverse. Le RAG menzionate in precedenza possono fornire risultati molto più affidabili in questo caso. Se vengono utilizzate per la ricerca su Pubmed, ad esempio, la pertinenza dei risultati della ricerca può essere notevolmente migliorata [6]. Un altro vantaggio di questo metodo è che gli studi trovati possono essere aggiunti al LLM come contesto e tutte le sue funzionalità, come la sintesi, la traduzione e l’analisi, possono essere utilizzate nel lavoro originale.
I moderni LLM offrono anche la possibilità di fornire manualmente un contesto aggiuntivo durante l’indagine. Ad esempio, è possibile allegare uno studio trovato e quindi riassumerlo e analizzarlo rapidamente. Tuttavia, va notato che c’è un limite alla “grandezza” di una query, soprattutto con le versioni gratuite degli LLM. Pertanto, è necessario verificare in ogni caso la dimensione effettiva possibile dell’input o del contesto (limite del contesto). Inoltre, queste sintesi non sono esenti da allucinazioni.
Caso di vignetta – Parte 3
Purtroppo, la colonscopia di follow-up di qualche settimana dopo ha rivelato una diagnosi di adenocarcinoma del colon sigmoideo, senza evidenza di metastasi locali o a distanza (stadio UICC I).
Il collega dello studio non sa come comunicare al meglio i risultati sfavorevoli alla giovane madre. Utilizza un LLM per prepararsi alla difficile conversazione.
Durante il consulto, si avvale di un LLM per spiegare i fatti medici alla paziente in modo semplice e nella sua lingua madre portoghese. Su richiesta del paziente, fa anche tradurre la sua breve relazione medica in portoghese da un LLM.
Gestione delle conversazioni
A prima vista, sembra controintuitivo chiedere a una macchina una consulenza in quella che dovrebbe essere la “disciplina paragonabile” umana della comunicazione. Tuttavia, poiché la funzione principale dei LLM è quella di imitare il più possibile il linguaggio umano, questo approccio non sembra più così inverosimile a un secondo sguardo. Di conseguenza, alcuni studi hanno già dimostrato che i moderni LLM sono in grado di dare risposte che contengono elementi di ’empatia’, che vengono poi interpretati come ’empatici’ dalla controparte umana [7]. Con le opportune indicazioni, si possono riprodurre varie tecniche di conduzione della conversazione e varianti di conversazione, che possono dare maggiore sicurezza soprattutto ai medici inesperti. Naturalmente, questo non esime il medico dalla comunicazione diretta ed empatica finale con il paziente.
Educazione del paziente
Se istruiti in modo appropriato, i LLM sono molto bravi a presentare contenuti medici specialistici in un linguaggio facile da capire. Pertanto, vale certamente la pena di provare a utilizzare strumenti basati sulle LLM nell’educazione dei pazienti. Tuttavia, è importante che il paziente continui a essere seguito da vicino da un medico. Il dovere del medico di fornire informazioni non può essere delegato a un LLM.
Traduzione di
Gli LLM possono tradurre molto bene tra lingue diverse. Questo funziona non solo con le lingue naturali, ma anche con i costrutti linguistici artificiali, come i linguaggi di programmazione. Gli LLM che sono stati addestrati specificamente per le traduzioni (ad esempio deepl.com) sono probabilmente ancora superiori ai generalisti (ad esempio ChatGPT) in termini di accuratezza, sebbene anche questi ultimi forniscano risultati impressionanti, soprattutto nelle ultime versioni. In termini di idoneità specifica per le traduzioni mediche, è chiaro che i piccoli LLM addestrati specificamente per questo compito sono attualmente ancora superiori ai modelli di grandi dimensioni [8]. La traduzione funziona in modo significativamente peggiore se la lingua desiderata è raramente presente nei dati di formazione.
Nel complesso, l’applicazione è attualmente limitata nel settore medico per due motivi: Da un lato, non è possibile caricare e tradurre interi documenti originali per motivi di protezione dei dati; dall’altro, il medico traduttore rimane il responsabile ultimo dell’accuratezza del contenuto, il che significa che per i rapporti critici è ancora necessaria una traduzione professionale. Se si ricorre agli LLM, è consigliabile tradurre solo in lingue in cui le traduzioni stesse possano essere verificate almeno per la loro plausibilità.
Caso di vignetta – Parte 4
L’emicolectomia sinistra pianificata viene eseguita senza complicazioni. Il tumore primario può essere completamente rimosso e i linfonodi mesenterici asportati sono liberi dal tumore. Nel post-operatorio, la paziente si riprende dall’intervento senza problemi ed è in grado di tornare a casa dopo poco tempo. Rimane libera dal tumore durante il trattamento oncologico successivo.
Il chirurgo viscerale che esegue l’intervento utilizza un LLM per creare le note per la consultazione di ammissione e i rapporti sull’operazione e sulla dimissione. Infine, l’amministrazione dell’ospedale che esegue l’intervento utilizza un LLM per pre-codificare il caso secondo lo Swiss-DRG dalla documentazione disponibile nel sistema informativo ospedaliero (HIS).
Segnalazione
La generazione di nuovi testi è una disciplina fondamentale dei moderni LLM. Di solito si ottiene una qualità semantica molto buona. La qualità del contenuto, d’altra parte, dipende fortemente dal contesto disponibile. Più dettagli sono disponibili per l’LLM, più accurato sarà il testo generato. Nella pratica clinica quotidiana, i rapporti standardizzati sono quindi principalmente adatti alla generazione automatica, ad esempio operazioni standard, interventi o richieste di rimborso. I referti più complessi con un ampio contesto clinico hanno molto meno successo, in quanto dovrebbero essere generati direttamente dal sistema informativo dell’ospedale o dello studio medico e avere accesso all’intero contesto terapeutico, cosa che – allo stato attuale – non è ancora sufficientemente riuscita.
Se i referti vengono generati con gli LLM, è responsabilità del medico registratore verificare la plausibilità del contenuto generato e approvarlo. Questo aspetto non deve essere sottovalutato, in quanto gli errori nel contenuto sono spesso più difficili da rilevare grazie alla buona qualità semantica. Anche la protezione dei dati deve essere garantita in ogni momento, soprattutto se all’LLM vengono fornite intere storie mediche come contesto.
Note di conversazione
Sempre più spesso arrivano sul mercato anche prodotti che utilizzano microfoni (ad esempio sugli smartphone) per registrare le conversazioni con i pazienti – anche in dialetto (!) – e trascriverle in linguaggio scritto utilizzando un LLM e, se necessario, strutturarle e riassumerle per l’anamnesi. Anche in questo caso, si applicano le stesse misure precauzionali e gli stessi standard in termini di allucinazioni e condizioni quadro medico-legali, che devono essere richieste di conseguenza dai produttori di software. Inoltre, molte questioni relative agli aspetti legali della richiesta di questi file audio non sono ancora state chiarite. In ogni caso, tutte le parti coinvolte devono essere d’accordo con le registrazioni.
Codifica/classificazione
Riconoscere i modelli anche nei dati non strutturati è una capacità importante dei LLM. L’idea che i LLM possano ricavare informazioni strutturate dalla grande quantità di dati non strutturati a testo libero che vengono generati quotidianamente nella documentazione clinica e quindi rendere accessibile l’elaborazione di questi dati per la fatturazione o la statistica, ad esempio, è altrettanto promettente. Questo è possibile, ma il LLM deve essere formato in modo specifico per questo. I soliti ‘LLM generalisti’ sono molto meno affidabili quando si tratta di codifica/classificazione. Spesso si confondono cataloghi e codici diversi, oppure i codici vengono semplicemente inventati (allucinati).
Tuttavia, è probabilmente solo una questione di tempo prima che le LLM opportunamente specializzate trovino spazio nei software di codifica. Ma anche in questo caso, i risultati dovranno ancora essere controllati per la plausibilità e approvati da codificatori umani per il momento, soprattutto perché l’insieme puro di regole (ad esempio SwissDRG) non è disponibile in forma strutturata, cosa che in genere sarebbe altamente auspicabile.
Sommario
Come ogni innovazione tecnologica, l’uso dei LLM nella pratica clinica quotidiana offre sia opportunità che rischi. Non è opportuno né fidarsi ciecamente né rifiutare rigidamente. Le consigliamo di familiarizzare con la nuova tecnologia e di limitarne inizialmente l’uso a un compito semplice in un’area in cui ha un alto livello di competenza. In questo modo, potrà farsi rapidamente un’idea delle possibilità e dei limiti degli LLM e, da lì, espandere lentamente il loro utilizzo. Prima di qualsiasi utilizzo in un contesto medico, tuttavia, occorre sempre tenere conto delle normative amministrative, legali ed etiche applicabili.
In generale, le nuove tecnologie e terapie fanno parte della vita quotidiana dei medici. Abbiamo imparato ad affrontarle con una sana dose di scetticismo e a non utilizzarle semplicemente in modo acritico sui nostri pazienti. Dobbiamo anche applicare questi principi scientifici di efficacia e appropriatezza quando utilizziamo le LLM nella pratica clinica quotidiana e pretenderli dai fornitori di questi strumenti, soprattutto perché i problemi più fondamentali delle LLM – allucinazioni e riproducibilità – sono ancora irrisolti e forse lo rimarranno. In questo contesto, si dovrà anche discutere se, come già avviene per i sistemi di riconoscimento vocale puro, i compromessi qualitativi debbano essere accettati come inevitabili.
A queste condizioni, nei prossimi mesi e anni potremo riuscire a utilizzare questa nuova tecnologia nella pratica clinica quotidiana, a vantaggio nostro e dei nostri pazienti.
Messaggi da portare a casa
- I grandi modelli linguistici (LLM) generano linguaggio, non conoscenza!
- Se utilizzate in modo mirato, le LLM possono anche fornire un utile supporto nella pratica clinica quotidiana.
- Raccomandiamo di acquisire una propria esperienza per poter valutare in modo più affidabile i benefici e i rischi.
- Molte questioni normative, di protezione dei dati ed etiche rimangono irrisolte, soprattutto nel settore medico. Non tutto ciò che funziona è permesso! La responsabilità rimane in ultima analisi del medico che utilizza il dispositivo.
| Grazie a |
| Gli autori desiderano ringraziare Frederic Ehrler, Team Leader di Ricerca e Sviluppo (R&D) dell’Ospedale Universitario di Ginevra, e il resto del Consiglio SGMI per la loro collaborazione al progetto originale MENTOR 2023 [1]. |
| Conflitti di interesse |
| Gli autori non hanno conflitti di interesse e, in particolare, non hanno alcun legame con OpenAI e ChatGPT. Questi LLM sono stati utilizzati come esempi, in quanto probabilmente sono i più familiari ai lettori. Le affermazioni contenute nell’articolo si applicano essenzialmente a tutti gli LLM disponibili. Gli autori fanno entrambi parte del consiglio direttivo della Società Svizzera di Informatica Medica (SGMI), vedi box informativo. |
Letteratura:
- Dürst L, et al.: ChatGPT im klinischen Alltag. Schweizerische Gesellschaft für Medizinische Informatik 2023; https://sgmi-ssim.org/wp-content/uploads/2023/10/Mentor-2023-ChatGPT-de.pdf.
- Coda-Forno J, et al.: Inducing anxiety in large language models can induce bias; doi: 10.48550/arXiv.2304.11111.
- Bicknell BT, et al.: ChatGPT-4 Omni Performance in USMLE Disciplines and Clinical Skills: Comparative Analysis. JMIR medical education 2024; 10: e63430; doi: 10.2196/63430.
- Hager P, et al.: Evaluation and mitigation of the limitations of large language models in clinical decision-making. Nature Medicine 2024; 30: 2613–2622; doi: 10.1038/s41591-024-03097-1.
- Deutsche Gesellschaft für Gastroenterologie, Verdauungs- und Stoffwechselkrankheiten e.V., S3-Leitlinie Divertikelkrankheit/Divertikulitis, Version 2.1, 2021; https://register.awmf.org/de/leitlinien/detail/021-020.
- Thomo A: PubMed Retrieval with RAG Techniques. Studies in health technology and informatics 2024; 316: 652–653; doi: 10.3233/SHTI240498.
- Sorin V, et al.: Large Language Models and Empathy: Systematic Review. Journal of medical Internet 2024; 26: e52597; doi: 10.2196/52597.
- Keles B, et al.: LLMs-in-the-loop Part-1: Expert Small AI Models for Bio-Medical Text Translation; doi: 10.48550/arXiv.2407.12126.
- Promptingtipps. Digital Learning Hub Sek II, Zürich; https://dlh.zh.ch/home/genki/promptingtipps.
InFo NEUROLOGIE & PSYCHIATRIE 2025; 23(1): 6–11