Com a disponibilização pública do ChatGPT 3.5 no outono de 2022, o mais tardar, a inteligência artificial no sentido de grandes modelos linguísticos (LLM ) está na boca de toda a gente. No entanto, esquece-se muitas vezes que este é apenas o ponto final provisório de décadas de desenvolvimento da inteligência artificial, que, apesar do seu grande potencial, ainda tem muitas limitações. Para os médicos em exercício, coloca-se a questão de saber como é que esta tecnologia pode ser utilizada de forma sensata na prática clínica quotidiana – e como é que é melhor não a utilizar.
Pode fazer o teste CME na nossa plataforma de aprendizagem depois de rever os materiais recomendados. Clique no botão seguinte:
Com a disponibilização pública do ChatGPT 3.5 no outono de 2022, o mais tardar, a inteligência artificial no sentido de grandes modelos linguísticos (LLM ) está na boca de toda a gente. No entanto, esquece-se muitas vezes que este é apenas o ponto final provisório de décadas de desenvolvimento da inteligência artificial, que, apesar do seu grande potencial, ainda tem muitas limitações.
Para os médicos em exercício, coloca-se a questão de saber como esta tecnologia fascinante pode ser utilizada de forma sensata na prática clínica quotidiana – e como não a utilizar. Com este CME, queremos oferecer-lhe uma ajuda concreta.
Vinheta de caso – Parte 1
Uma doente de 44 anos apresenta-se no consultório do médico de família com dores no abdómen inferior esquerdo. Os sintomas começaram há alguns dias e estão agora a aumentar de forma constante. A doente encontra-se em bom estado de saúde geral, com sinais vitais estáveis. Tem uma sensibilidade no abdómen inferior esquerdo com uma dor mínima. Não tem febre, os valores da inflamação estão ligeiramente elevados. Suspeita-se de diverticulite.
O jovem colega do médico de clínica geral está entusiasmado com as possibilidades dos grandes modelos linguísticos e gostaria de os utilizar na sua prática clínica diária.
Fundamentos técnicos [1]
Os modelos de grande linguagem (LLM) são um ramo da inteligência artificial ou da aprendizagem automática que se ocupa do processamento da linguagem natural. São constituídos por uma rede com dezenas de camadas e milhares de milhões ou provavelmente triliões de ligações (parâmetros). Uma vez que esta estrutura é semelhante à de um cérebro biológico, o termo “rede neural” tornou-se conhecido.
A rede é treinada com base num extenso corpus de texto que está normalmente disponível gratuitamente na Internet. Nem todos os fabricantes revelam o âmbito exato dos dados de treino. A formação é automatizada (não supervisionada) e conduzida por humanos (parcialmente supervisionada) e consome muito tempo e recursos. A supervisão humana é necessária para aumentar a qualidade da aprendizagem e para garantir que não predomina uma linguagem negativa ou agressiva. Ao mesmo tempo, esta supervisão humana é também uma área problemática, uma vez que os examinadores são frequentemente mal pagos e, possivelmente, têm uma formação insuficiente.
Durante o treino, os dados de treino são fragmentados (tokenizados ) em pequenos fragmentos, como palavras ou partes curtas de palavras, e as ligações entre eles são ponderadas na rede. As ligações que ocorrem frequentemente são reforçadas e as raras são enfraquecidas. Como resultado, a rede desenvolve um conhecimento profundo da estrutura da língua nos dados de treino. Dependendo das definições básicas e dos dados de treino, uma rede pode ser especializada para tarefas específicas, por exemplo, a tradução de línguas. Os LLM atualmente em estudo são, na sua maioria, “generalistas”, sem uma especialização clara.
| Sociedade Suíça de Informática Médica (SGMI) |
| A Sociedade Suíça de Informática Médica (SGMI) promove o estudo, o desenvolvimento e a utilização de ferramentas informáticas no sector da saúde. Enquanto organização neutra, o aspeto científico (eficácia, prova de benefício, conveniência) é importante para nós na divulgação de ferramentas informáticas na prática clínica quotidiana (informática médica baseada em provas). Por conseguinte, o SGMI também se considera um parceiro prudente e fiável no domínio da integração de sistemas, da conceção de processos, da transferência de dados e da utilização num ecossistema sociotécnico de cuidados de saúde o mais normalizado possível. |
| No âmbito das suas actividades, o SGMI organiza anualmente, no outono, o Swiss ehealthsummit. Além disso, publica regularmente diretrizes sobre temas importantes da informática médica (MENTOR). Em setembro de 2023, publicou uma MENTOR sobre o tema “LLMs na prática clínica diária”, que serviu de base para este artigo [1]. |
| > www.sgmi-ssim.ch |
Uma vez concluído o treino, a rede e as ligações ponderadas permanecem inalteradas. Neste estado, já não é possível efetuar alterações fundamentais à rede, mas o comportamento da resposta ainda pode ser definido. Por exemplo, pode definir a duração da resposta, o estilo de linguagem, as repetições de palavras e a aleatoriedade.
Pode agora interagir com esta rede totalmente treinada. Isto é frequentemente feito através de um chat num sítio Web ou de uma aplicação para smartphone, mas também são possíveis ligações técnicas diretas através de interfaces Web (ver exemplos na Tabela 1). O pedido de informação (prompt) é preparado e introduzido no LLM. O LLM gera então, iterativamente, uma resposta palavra a palavra (mais precisamente: token a token). A palavra seguinte é selecionada a partir de uma lista das palavras seguintes mais prováveis. Esta seleção é aleatória até um certo ponto, para que a geração de texto pareça mais criativa (“humana”). O grau de aleatoriedade pode ser definido pelos fornecedores do LLM ou influenciado através de uma solicitação específica, mas em qualquer caso exclui a reprodutibilidade completa da resposta (também porque nem todos os pedidos são respondidos com a mesma instância dos LLMs disponíveis).
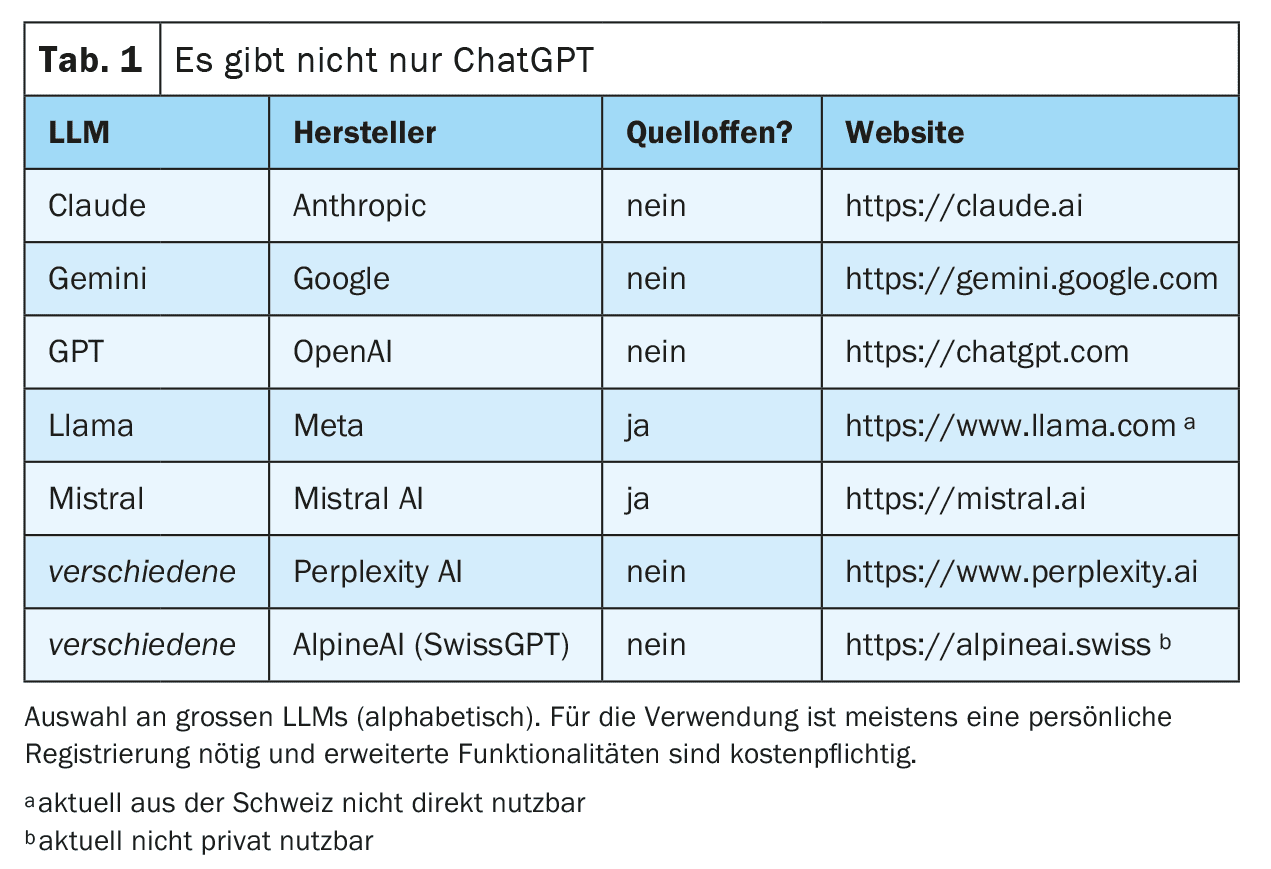
Para obter os melhores resultados possíveis, é importante seguir certas regras ao efetuar uma consulta e fornecer um contexto tão preciso quanto possível. Este processo – gerar as melhores consultas possíveis – é conhecido como engenharia de pedidos (Tabela 2). Dependendo do tipo de pedido, os grandes fornecedores podem também utilizar diferentes LLM “especializados” em segundo plano. A Figura 1 dá-lhe uma visão simplificada do funcionamento de um LLM.

Vantagens e desvantagens
Os LLM modernos são surpreendentemente bons a imitar o discurso humano. Esta capacidade é basicamente independente da língua de entrada utilizada, desde que esta língua esteja disponível em quantidade suficiente nos dados de treino.
Nos LLM mais recentes, uma grande parte do conhecimento livre da Internet está tecnicamente disponível. No entanto, devido ao seu modo de funcionamento, não é possível a um LLM desenvolver os seus próprios conceitos e pensamentos (criatividade genuína), mas apenas recombinar e reproduzir o conhecimento disponível a partir do corpus de texto.
Lembre-se: os LLM geram linguagem, não conhecimento!
No entanto, o modo de funcionamento descrito tem também algumas desvantagens que os utilizadores devem ter sempre em conta. Por exemplo, os LLMs tendem a inventar respostas (alucinar) em vez de admitir a sua ignorância. Isto tem a ver com o facto de, nestes casos, as palavras menos prováveis serem simplesmente adicionadas à resposta e acontece especialmente quando uma resposta é baseada em dados de treino limitados, por exemplo, no caso de uma doença rara. Embora este risco possa ser reduzido através de uma boa configuração dos modelos, as alucinações não reconhecidas continuam a ser um risco importante quando se utilizam os LLM. Além disso, os LLMs também podem ser influenciados negativamente por estímulos direcionados [2].
Devido à falta de uma compreensão global e à seleção aleatória da próxima ficha, os LLM revelam problemas ao lidar com a lógica e a matemática. Isto torna mais difícil a reprodutibilidade de uma resposta e, por conseguinte, a sua utilização na investigação e num contexto médico-legal.
Outro problema das LLM clássicas é a atualidade dos dados, uma vez que o conhecimento da LLM deixa de ser alargado após a conclusão da formação. As LLM modernas oferecem a opção de fornecer contexto adicional e atualizado, por exemplo, a partir de uma pesquisa bibliográfica (retrieval augmented generation, RAG), o que atenua o problema e melhora a fiabilidade da resposta. Neste contexto, o LLM pode mesmo fornecer informações fiáveis sobre a fonte, o que de outra forma não seria possível. O utilizador deve, portanto, estar ciente da variante de LLM com que está a comunicar.
Por fim, há toda uma série de aspectos jurídicos, regulamentares e éticos, como a proteção de dados, a responsabilidade e os direitos de autor, que ainda não foram suficientemente esclarecidos pela sociedade em geral e que são fonte de grande incerteza para a utilização correta dos LLM, nomeadamente na prática médica quotidiana. Os sistemas com autonomia nacional (nomeadamente no domínio da proteção de dados e da legislação suíça) podem oferecer uma solução parcial neste domínio. A Health Info Net AG (HIN) – tradicionalmente associada à segurança do intercâmbio de dados no sistema de saúde suíço – parece estar a estabelecer uma parceria com o SwissGPT neste domínio. No entanto, ainda não é possível avaliar a penetração e a aceitação no mercado.
Lembre-se: nem tudo o que funciona é permitido!
Domínios de aplicação
Vinheta de caso – Parte 2
Para se precaver, o jovem colega, ainda um pouco inexperiente, consulta um médico de medicina legal, que também refere a diverticulite como o diagnóstico diferencial mais provável. O médico de família também mencionou a torção ou quisto do ovário e cálculos renais como possíveis diagnósticos diferenciais. O exame de ultrassom focalizado revela achados consistentes com diverticulite. Não há indicações de uma evolução localmente complicada.
O médico sugere-lhe uma terapêutica antibiótica em ambulatório e uma colonoscopia de seguimento após algumas semanas. O colega e o doente concordam com esta proposta de tratamento. O doente recupera como planeado em poucos dias.
Fazer diagnósticos e raciocínio diagnóstico
O facto de o vasto conhecimento do Dr. ChatGPT apoiar os médicos no processo de diagnóstico e nas decisões de tratamento parece ser uma aplicação óbvia.
Afinal de contas, os LLMs modernos passam no exame de estado de medicina dos EUA (USMLE) com pontuações elevadas de mais de 90% com os LLMs mais recentes [3]. Não é de surpreender que, numa inspeção mais atenta, estas vinhetas de casos sejam muito estruturadas e resumam toda a informação necessária para fazer um diagnóstico ou responder à pergunta. Além disso, muitas das perguntas já estavam provavelmente presentes no conjunto de dados de treino dos LLM.
Torna-se mais interessante quando os LLMs têm de adquirir informações sobre os próprios pacientes num processo de diagnóstico. Neste caso, os resultados são muito menos impressionantes [4]. Isto também não é realmente surpreendente, pois muitas informações ainda não estão disponíveis ou não estão disponíveis em formato digital, especialmente na fase inicial de um diagnóstico, mas um MLT precisa das informações mais detalhadas possíveis para alcançar os melhores resultados. Além disso, a sua fraqueza fundamental em lidar com números dificulta-lhe a interpretação dos sinais vitais e dos valores laboratoriais.
Devido ao seu modo de funcionamento, um LLM é atualmente adequado sobretudo como meio de reconhecimento de possíveis padrões a partir de um conjunto de informações fornecidas que podem ainda permanecer ocultas para o médico, ou seja, principalmente para o diagnóstico diferencial.
A utilização generalizada na prática clínica diária para apoio à decisão é também limitada pelos requisitos aplicáveis em matéria de responsabilidade, proteção de dados e certificação como produto médico.
Recomendações de tratamento e pesquisa bibliográfica
Uma vez que a maior parte das diretrizes de tratamento estão disponíveis gratuitamente em linha, não é surpreendente que os MLT também possam fazer recomendações de tratamento em conformidade com as diretrizes. O principal problema aqui é a limitação temporal dos dados de treinamento. Muitas vezes, as diretrizes e os resultados de estudos mais recentes não são treinados no LLM. No caso do exemplo específico, a opção de tratamento mais recente “watch & wait” para diverticulite não complicada e sem factores de risco está obviamente ausente [5]. As obras de referência e as bases de dados bibliográficas de elevada qualidade e mantidas editorialmente têm ainda a vantagem de estarem actualizadas.
Outro fator de complicação é a incapacidade dos LLM clássicos de citarem a fonte exacta. Não será sempre claro quais as versões das diretrizes a que o LLM se refere e se misturou diferentes diretrizes. Os RAGs mencionados acima podem fornecer resultados muito mais fiáveis neste caso. Se forem utilizadas para pesquisar na Pubmed, por exemplo, a relevância dos resultados da pesquisa pode ser significativamente melhorada [6]. Outra vantagem deste método é que os estudos encontrados podem também ser adicionados ao LLM como contexto e todas as suas funcionalidades, tais como resumir, traduzir e analisar, podem depois ser utilizadas no trabalho original.
Os LLM modernos oferecem também a possibilidade de fornecer manualmente um contexto adicional durante a pesquisa. Por exemplo, pode anexar um estudo encontrado e, assim, resumi-lo e analisá-lo rapidamente. No entanto, deve ter em conta que existe um limite para o “tamanho” de uma consulta, especialmente nas versões gratuitas dos LLM. O tamanho real possível da entrada ou do contexto (limite de contexto) deve, portanto, ser verificado em cada caso. Além disso, estes resumos não estão isentos de alucinações.
Vinheta de caso – Parte 3
Infelizmente, a colonoscopia de seguimento realizada algumas semanas mais tarde revelou um diagnóstico de adenocarcinoma do cólon sigmoide sem evidência imagiológica de metástases locais ou à distância (estádio I da UICC).
O seu colega de consultório não tem a certeza da melhor forma de comunicar os resultados desfavoráveis à jovem mãe. Recorre a um LLM para se preparar para a difícil conversa.
Durante a consulta, recorre a um LLM para explicar os factos médicos à paciente de forma simples e no seu português nativo. A pedido da paciente, o seu breve relatório médico é também traduzido para português por um LLM.
Gestão da conversação
À primeira vista, parece contra-intuitivo pedir conselhos a uma máquina no que é suposto ser a “disciplina paradigmática” humana da comunicação. No entanto, uma vez que a principal função dos LLM é imitar o mais possível o discurso humano, esta abordagem já não parece tão rebuscada à segunda vista. Assim, alguns estudos já demonstraram que os MLT modernos são capazes de dar respostas que contêm elementos de “empatia”, que são depois interpretadas como “empáticas” pelo interlocutor humano [7]. Com os estímulos adequados, podem ser reproduzidas várias técnicas de condução da conversa e variantes de conversa, o que pode dar mais confiança aos médicos inexperientes. Naturalmente, isto não dispensa o médico da comunicação empática e direta com o doente.
Educação dos doentes
Quando instruídos de forma adequada, os LLMs são muito bons a apresentar conteúdos médicos especializados numa linguagem fácil de compreender. Portanto, vale a pena tentar usar ferramentas baseadas em MLMs na educação de pacientes. No entanto, é importante que o doente continue a ser acompanhado de perto por um médico. O dever do médico de fornecer informações não pode ser delegado a um MLM.
Tradução de
Os LLMs podem traduzir muito bem entre diferentes línguas. Isto funciona não só com línguas naturais, mas também com construções linguísticas artificiais, como as linguagens de programação. As LLMs que foram especificamente treinadas para traduções (por exemplo, deepl.com) são provavelmente ainda superiores às generalistas (por exemplo, ChatGPT) em termos de precisão, embora estas últimas também apresentem resultados impressionantes, especialmente nas versões mais recentes. Em termos de adequação especificamente para traduções médicas, é evidente que os pequenos LLMs que foram especificamente treinados para esta tarefa continuam atualmente a ser superiores aos grandes modelos [8]. A tradução funciona significativamente pior se a língua desejada raramente estiver presente nos dados de treino.
De um modo geral, a aplicação é atualmente limitada no domínio médico por duas razões: Por um lado, os documentos originais completos não podem ser carregados e traduzidos devido a preocupações com a proteção de dados; por outro lado, o médico tradutor continua a ser o principal responsável pela exatidão do conteúdo, o que significa que continua a ser necessária uma tradução profissional para relatórios críticos. Se recorrer a LLM, é aconselhável que traduza apenas para línguas em que a plausibilidade das traduções possa ser, pelo menos, verificada.
Vinheta de caso – Parte 4
A hemicolectomia esquerda planeada é realizada sem complicações. O tumor primário pode ser completamente removido e os gânglios linfáticos mesentéricos removidos estão livres de tumores. No pós-operatório, a doente recupera da operação sem problemas e pode regressar a casa passado pouco tempo. No pós-operatório oncológico, mantém-se livre de tumores.
O cirurgião visceral que efectua a operação utiliza um LLM para criar as notas da consulta de admissão e os relatórios de operação e de alta. Por fim, a administração do hospital que efectua a operação utiliza um LLM para pré-codificar o caso de acordo com o Swiss-DRG a partir da documentação disponível no sistema de informação hospitalar (HIS).
Relatórios
A produção de novos textos é uma disciplina essencial dos modernos LLM. A qualidade semântica é geralmente muito boa. A qualidade do conteúdo, por outro lado, depende muito do contexto disponível. Quanto mais detalhes estiverem disponíveis para a MLT, mais preciso será o texto gerado. Na prática clínica quotidiana, os relatórios normalizados são, portanto, principalmente adequados para a geração automática, por exemplo, operações normalizadas, intervenções ou pedidos de reembolso. Relatórios mais complexos, com muito contexto clínico, são muito menos bem sucedidos, uma vez que teriam de ser gerados diretamente a partir do sistema de informação do hospital ou da clínica e ter acesso a todo o contexto do tratamento, o que – na situação atual – ainda não é suficientemente bem sucedido.
Se os relatórios forem gerados com LLM, é da responsabilidade do médico responsável pelo registo verificar a plausibilidade do conteúdo gerado e aprová-lo. Isto não deve ser subestimado, uma vez que os erros no conteúdo são frequentemente mais difíceis de detetar devido à boa qualidade semântica. Este aspeto não deve ser subestimado, uma vez que os erros de conteúdo são frequentemente mais difíceis de detetar devido à boa qualidade semântica. A proteção dos dados também deve ser garantida em todos os momentos, especialmente se histórias médicas completas forem fornecidas ao LLM como contexto.
Notas de conversa
Cada vez mais, estão a ser lançados no mercado produtos que utilizam microfones (por exemplo, em smartphones) para gravar conversas com os pacientes – mesmo em dialeto (!) – e transcrevê-las para a linguagem escrita através de um LLM e, se necessário, estruturá-las e resumi-las para a história clínica. Também aqui se aplicam as mesmas medidas de precaução e normas em matéria de alucinações e condições de enquadramento médico-legal, que devem ser exigidas em conformidade pelos fabricantes de software. Além disso, muitas questões relacionadas com os aspectos jurídicos do pedido destes ficheiros áudio ainda não foram esclarecidas. Em todo o caso, todas as partes envolvidas devem estar de acordo com as gravações.
Codificação/classificação
O reconhecimento de padrões, mesmo em dados não estruturados, é uma capacidade importante dos LLMs. A ideia de que os LLMs poderiam derivar informações estruturadas da grande quantidade de dados não estruturados de texto livre que são gerados diariamente na documentação clínica e, assim, tornar o processamento desses dados acessível para faturação ou estatísticas, por exemplo, é correspondentemente promissora. Isto é possível, mas o LLM deve ter uma formação específica para o efeito. Os habituais “LLM generalistas” são muito menos fiáveis quando se trata de codificação/classificação. Os diferentes catálogos e códigos são frequentemente misturados ou os códigos são simplesmente inventados (alucinados).
No entanto, é provavelmente apenas uma questão de tempo até que os LLMs devidamente especializados encontrem o seu lugar no software de codificação. Mas também neste caso, os resultados terão ainda de ser verificados quanto à sua plausibilidade e aprovados por codificadores humanos, especialmente porque o conjunto puro de regras (por exemplo, SwissDRG) não está disponível numa forma estruturada, o que seria geralmente muito desejável.
Resumo
Como qualquer inovação tecnológica, a utilização dos LLM na prática clínica quotidiana oferece oportunidades e riscos. Nem a confiança cega nem a rejeição estrita são convenientes. Recomendamos que se familiarize com a nova tecnologia e que, inicialmente, limite a sua utilização a uma tarefa simples numa área em que tenha um elevado nível de especialização. Desta forma, pode rapidamente ter uma boa noção das possibilidades e limitações dos LLMs e, a partir daí, expandir lentamente a sua utilização. No entanto, antes de qualquer utilização num contexto médico, deve ter sempre em conta os regulamentos administrativos, legais e éticos aplicáveis.
De um modo geral, as novas tecnologias e terapias fazem parte da vida quotidiana dos médicos. Aprendemos a abordá-las com uma dose saudável de ceticismo e a não as utilizar simplesmente de forma acrítica nos nossos doentes. Temos também de aplicar estes princípios científicos de eficácia e de adequação quando utilizamos os MLT na prática clínica quotidiana e de os exigir aos fornecedores destes instrumentos, tanto mais que os problemas mais fundamentais dos MLT – alucinações e reprodutibilidade – ainda não estão resolvidos e talvez assim continuem. Neste contexto, terá também de se discutir se – tal como já acontece com os sistemas puros de reconhecimento da fala – os compromissos qualitativos devem ser aceites como inevitáveis.
Nestas condições, podemos conseguir, nos próximos meses e anos, utilizar esta nova tecnologia na prática clínica quotidiana, para nosso benefício e dos nossos doentes.
Mensagens para levar para casa
- Os grandes modelos linguísticos (LLM) geram linguagem, não conhecimento!
- Quando utilizados de forma orientada, os MMN podem também fornecer um apoio útil na prática clínica quotidiana.
- Recomendamos que adquira a sua própria experiência para poder avaliar os benefícios e os riscos de forma mais fiável.
- Muitas questões regulamentares, de proteção de dados e éticas continuam por resolver – especialmente no sector médico. Nem tudo o que funciona é permitido! Em última análise, a responsabilidade recai sobre o médico que utiliza o dispositivo.
| Agradecimentos a |
| Os autores gostariam de agradecer a Frederic Ehrler, chefe da equipa de Investigação e Desenvolvimento (I&D) do Hospital Universitário de Genebra, e ao resto do Conselho do SGMI pela sua colaboração no MENTOR 2023 original [1]. |
| Conflitos de interesse |
| Os autores não têm conflitos de interesse e, em particular, não têm qualquer ligação ao OpenAI e ao ChatGPT. Estes LLMs foram usados como exemplos, pois são provavelmente os mais familiares aos leitores. Os autores fazem parte da direção da Sociedade Suíça de Informática Médica (SGMI), ver caixa de informação. |
Literatura:
- Dürst L, et al.: ChatGPT im klinischen Alltag. Schweizerische Gesellschaft für Medizinische Informatik 2023; https://sgmi-ssim.org/wp-content/uploads/2023/10/Mentor-2023-ChatGPT-de.pdf.
- Coda-Forno J, et al.: Inducing anxiety in large language models can induce bias; doi: 10.48550/arXiv.2304.11111.
- Bicknell BT, et al.: ChatGPT-4 Omni Performance in USMLE Disciplines and Clinical Skills: Comparative Analysis. JMIR medical education 2024; 10: e63430; doi: 10.2196/63430.
- Hager P, et al.: Evaluation and mitigation of the limitations of large language models in clinical decision-making. Nature Medicine 2024; 30: 2613–2622; doi: 10.1038/s41591-024-03097-1.
- Deutsche Gesellschaft für Gastroenterologie, Verdauungs- und Stoffwechselkrankheiten e.V., S3-Leitlinie Divertikelkrankheit/Divertikulitis, Version 2.1, 2021; https://register.awmf.org/de/leitlinien/detail/021-020.
- Thomo A: PubMed Retrieval with RAG Techniques. Estudos em tecnologia da saúde e informática 2024; 316: 652-653; doi: 10.3233/SHTI240498.
- Sorin V, et al.: Large Language Models and Empathy: Systematic Review. Journal of medical Internet 2024; 26: e52597; doi: 10.2196/52597.
- Keles B, et al.: LLMs-in-the-loop Part-1: Expert Small AI Models for Bio-Medical Text Translation; doi: 10.48550/arXiv.2407.12126.
- Promptingtipps. Digital Learning Hub Sek II, Zürich; https://dlh.zh.ch/home/genki/promptingtipps.
InFo NEUROLOGIE & PSYCHIATRIE 2025; 23(1): 6–11