With the public availability of ChatGPT 3.5 in fall 2022 at the latest, artificial intelligence in the sense of large language models (L LMs) is on everyone’s lips. However, it is often forgotten that this is only the provisional end point of decades of development of artificial intelligence, which, despite its great potential, still has many limitations. The question for practising doctors is how this technology can be used sensibly in everyday clinical practice – and how it should not be used.
You can take the CME test on our learning platform after you have reviewed the recommended materials. Please click on the following button:
With the public availability of ChatGPT 3.5 in fall 2022 at the latest, artificial intelligence in the sense of large language models (L LMs) is on everyone’s lips. However, it is often forgotten that this is only the provisional end point of decades of development of artificial intelligence, which, despite its great potential, still has many limitations.
For the practicing physician, the question arises as to how this fascinating technology can be used sensibly in everyday clinical practice – and how not to use it. With this CME, we want to offer concrete assistance here.
Case vignette – Part 1
A 44-year-old female patient presents to the family doctor’s practice with left lower abdominal pain. The symptoms started a few days ago and are now steadily increasing. The patient is in good general health with stable vital signs. There is tenderness in the left lower abdomen with minimal tenderness. No fever, slightly elevated inflammation values. Diverticulitis is suspected.
The young colleague in the GP practice is enthusiastic about the possibilities of the large language models and would also like to use them in his everyday clinical practice.
Technical basics [1]
Large language models (LLMs) are a branch of artificial intelligence or machine learning that deals with natural language processing. They consist of a network with dozens of layers and billions to probably trillions of connections (parameters). As this structure is similar to a biological brain, the term “neural network” has become established.
The network is trained on an extensive text corpus that is usually freely available on the internet. Not all manufacturers disclose the exact scope of the training data. The training is both automated (unsupervised) and human-guided (partially supervised) and is extremely time-consuming and resource-intensive. Human supervision is necessary to increase the quality of learning and to ensure that negative or aggressive language does not predominate. At the same time, this human supervision is also a problem area, as the examiners are often underpaid and may be under-trained.
During training, the training data is fragmented (tokenized ) into small fragments such as words or short parts of words and the connections between them are weighted in the network. Frequently occurring connections are strengthened, rare ones are weakened. The network thus develops an in-depth knowledge of the structure of the language in the training data. Depending on the basic settings and training data, a network can be specialized for specific tasks, e.g. language translation. The LLMs currently in focus are mostly “generalists” with no clear specialization.
| Swiss Society for Medical Informatics (SGMI) |
| The Swiss Society for Medical Informatics (SGMI) promotes the study, development and use of IT tools in the healthcare sector. As a neutral organization, the scientific aspect (effectiveness, proof of benefit, expediency) is important to us in the dissemination of IT tools in everyday clinical practice (evidence-based medical informatics). Accordingly, the SGMI also sees itself as a prudent and reliable partner in the area of system integration, process design, data transfer and use in a socio-technical healthcare ecosystem that is as standard-oriented as possible. |
| As part of its activities, the SGMI organizes the annual Swiss ehealthsummit in autumn. It also publishes guidelines on important topics in medical informatics (MENTOR) at regular intervals. In September 2023, it published a MENTOR on the topic of “LLMs in everyday clinical practice”, which served as the basis for this article [1]. |
| > www.sgmi-ssim.ch |
Once training is complete, the network and the weighted connections remain unchanged. Fundamental changes to the network are no longer possible in this state, but the response behavior can still be set. For example, response length, language style, word repetitions and randomness can be set.
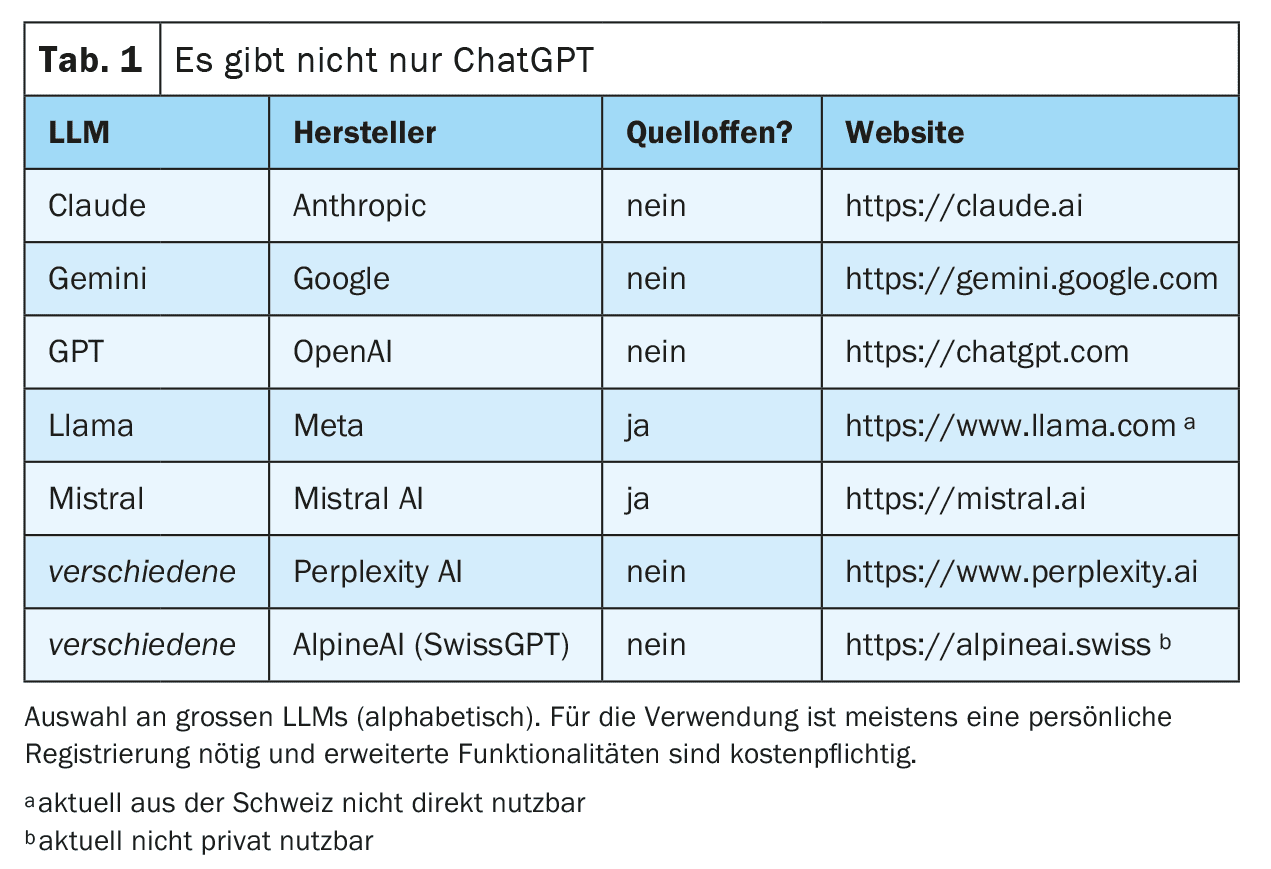
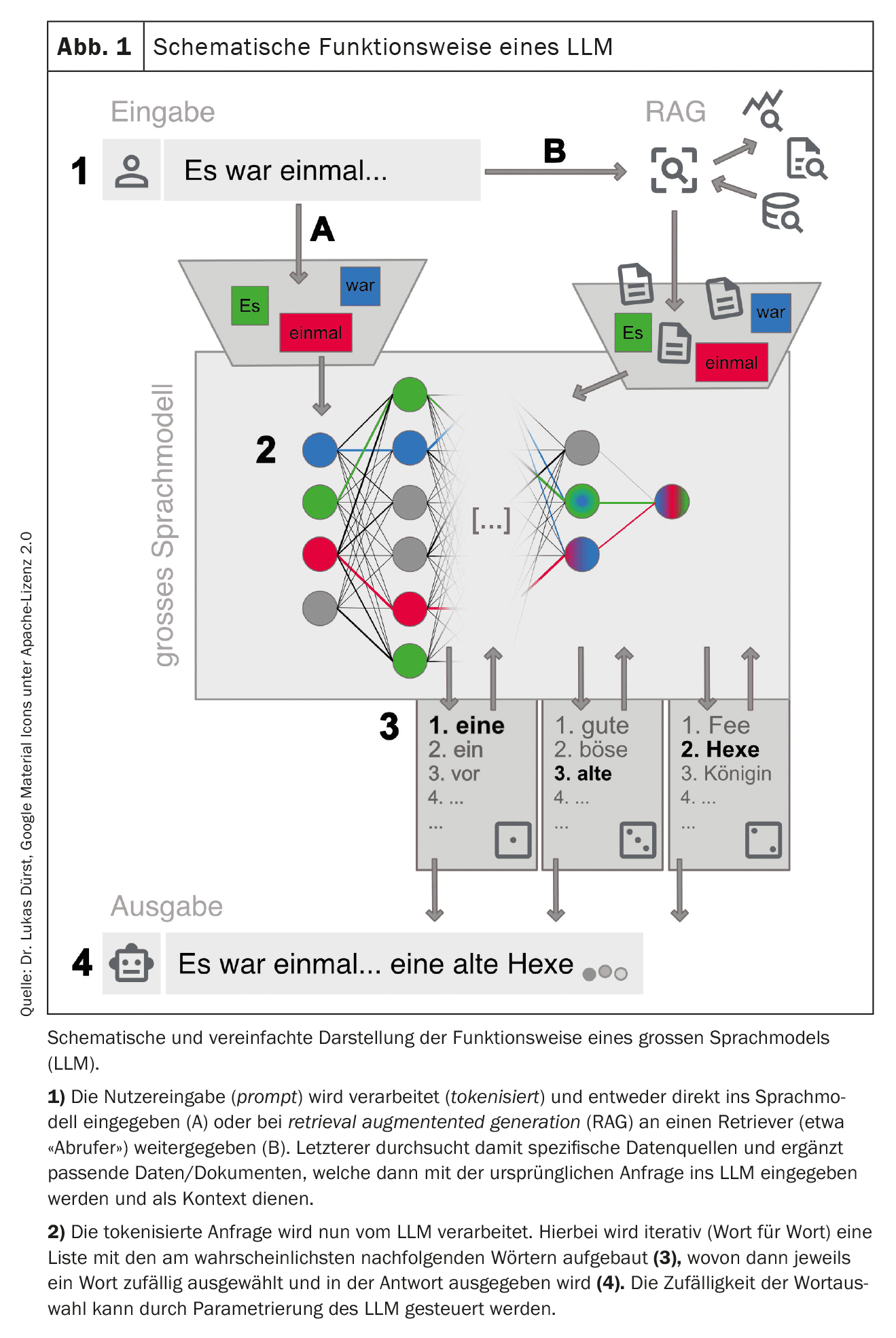
This trained network can now be interacted with. This is often done via a chat on a website or a smartphone application, but direct technical connections via web interfaces are also possible (see Table 1 for examples ). The request (prompt) is prepared and entered into the LLM. This is then used to iteratively generate a response word by word (more precisely: token by token). The next word is selected from a list of the most probable next words. This selection is random to a certain extent in order to make text generation appear more creative (“human”). The degree of randomness can be set by the suppliers of the LLM or influenced via targeted prompting, but in any case excludes complete reproducibility of the response (also because not every request is answered with the same instance of the available LLMs).
In order to obtain the best possible results, it is important to follow certain rules when making a query and to provide the most accurate context possible. This process – generating the best possible queries – is known as prompt engineering (Table 2). Depending on the type of request, large providers may also use different “specialized” LLMs in the background. Figure 1 provides a simplified overview of how an LLM works.

Advantages and disadvantages
Modern LLMs are surprisingly good at imitating human-like speech. This ability is basically independent of the input language used, as long as this language is available in sufficient quantity in the training data.
In the latest LLMs, a large part of the free knowledge from the Internet is technically available. Due to the way it works, however, it is not possible for an LLM to develop its own concepts and thoughts (genuine creativity), but merely to recombine and reproduce the available knowledge from the text corpus.
Note: LLMs generate language, not knowledge!
However, the described mode of operation also has some disadvantages that users must be aware of at all times. For example, LLMs tend to invent answers (hallucinate) instead of admitting ignorance. This has to do with the fact that in such cases less probable words are simply added to the answer and happens especially when an answer is based on limited training data, e.g. in the case of a rare disease. Although this risk can be reduced by good configuration of the models, unrecognized hallucinations remain a major risk when using LLMs. In addition, LLMs can also be negatively influenced by targeted prompting [2].
Due to the lack of an overarching understanding and the random selection of the next token, LLMs show problems in dealing with logic and mathematics. This makes the reproducibility of an answer and thus its use in research and in a medico-legal context more difficult.
Another problem with classic LLMs is the topicality of the data, as the knowledge of the LLM is no longer expanded after its training has been completed. Modern LLMs offer the option of providing additional, up-to-date context, e.g. from a literature search (retrieval augmented generation, RAG), which mitigates the problem and improves the reliability of the answer. In this context, the LLM can even provide reliable source information, which is otherwise not possible. The user must therefore be aware of which variant of LLMs they are communicating with.
Finally, there are a whole range of legal, regulatory and ethical aspects, such as data protection, liability and copyright issues, which are currently still not sufficiently clarified in society and which make the correct use of LLMs very uncertain, especially in everyday medical practice. Systems with domestic autonomy (particularly in the area of data protection and Swiss legislation) may offer a partial remedy here. Health Info Net AG (HIN) – traditionally associated with security in data exchange in the Swiss healthcare system – appears to be entering into a partnership with SwissGPT here. However, it is not yet possible to assess market penetration and acceptance.
Remember: Not everything that works is allowed!
Areas of application
Case vignette – Part 2
To be on the safe side, the still somewhat inexperienced young colleague consults an LLM, who also names diverticulitis as the most likely differential diagnosis. The LLM also mentioned ovarian torsion or cyst and kidney stones as possible differential diagnoses. The focused ultrasound examination reveals findings consistent with diverticulitis. There are no indications of a locally complicated course.
The LLM suggests outpatient antibiotic therapy and a follow-up colonoscopy after a few weeks. The colleague and the patient agree to this treatment proposal. The patient recovers as planned within a few days.
Making diagnoses and diagnostic reasoning
The fact that Dr. ChatGPT’s broad knowledge supports doctors in the diagnostic process and in treatment decisions seems to be an obvious application.
After all, modern LLMs pass the US medical state examination (USMLE) with high scores of over 90% with the latest LLMs [3]. This is not surprising on closer inspection, as these case vignettes are very structured and provide a summary of all the information required to make a diagnosis or answer the question. In addition, many of the questions were probably already present in the training data set of the LLMs.
It becomes more interesting when LLMs have to acquire information about patients themselves in a diagnostic process. Here, the results are much less impressive [4]. This is also not really surprising, as a great deal of information is either not yet available or not available in digital form, especially in the initial phase of a diagnosis, but an LLM needs the most detailed information possible to achieve the best results. In addition, their fundamental weakness in dealing with numbers makes it difficult for them to interpret vital signs and laboratory values.
Due to the way it works, an LLM is now mainly suitable as a means of recognizing possible patterns from a set of information provided, which may still remain hidden to the doctor, i.e. mainly for differential diagnosis.
Widespread use in everyday clinical practice for decision support is also limited by the applicable requirements with regard to liability, data protection and certification as a medical product.
Treatment recommendations and literature search
Since most treatment guidelines are freely available online, it is not surprising that LLMs can also make guideline-based treatment recommendations. The main problem here is the time limitation of the training data. The latest guidelines and study results are often not trained in the LLM. In the specific example case, the newer treatment option “watch & wait” for uncomplicated diverticulitis and missing risk factors is obviously missing [5]. High-quality, editorially maintained reference works and literature databases still have the advantage of being up-to-date.
Another complicating factor is the inability of the classic LLMs to cite the exact source. It will always remain unclear which guideline versions the LLM refers to and whether it has mixed different guidelines. The RAGs mentioned above can provide much more reliable results here. If they are used to search Pubmed, for example, the relevance of the search results can be significantly improved [6]. A further advantage of this method is that studies found can also be given to the LLM as context and all its functionalities such as summarization, translation and analysis can then be used in the original paper.
Modern LLMs also offer the option of providing additional context manually during the query. For example, a study found can be attached and thus quickly summarized and analyzed. However, it should be noted that there is a limit to how “large” a query can be, especially with the free versions of LLMs. The actual possible input or context size (context limit) should therefore be checked in each case. In addition, these summaries are not exempt from hallucinations.
Case vignette – Part 3
Unfortunately, the follow-up colonoscopy a few weeks later revealed a diagnosis of adenocarcinoma of the sigmoid colon with no imaging evidence of local or distant metastasis (UICC stage I).
The colleague in the practice is unsure how best to communicate the unpleasant findings to the young mother. He uses an LLM to prepare himself for the difficult conversation.
During the consultation, he uses an LLM to explain the medical facts to the patient simply and in her native Portuguese. At the patient’s request, he also has his brief medical report translated into Portuguese by an LLM.
Conversational
At first glance, it seems counter-intuitive to ask a machine for advice in the supposedly human “showpiece discipline” of communication. However, since the main function of LLMs is to imitate human speech as closely as possible, this approach no longer seems so far-fetched at second glance. Accordingly, some studies have already shown that modern LLMs are able to give answers that contain elements of “empathy”, which are then also interpreted as “empathic” by the human counterpart [7]. With the appropriate prompting, various techniques for conducting conversations and conversation variants can be played through, which can give inexperienced doctors in particular additional confidence. Of course, this does not release the doctor from the ultimate empathic and direct communication with the patient.
Patient education
When instructed appropriately, LLMs are very good at presenting specialist medical content in easy-to-understand language. It is therefore perfectly possible to attempt to use tools based on LLMs in patient education. However, it is important that the patient continues to be closely supervised by a doctor. The doctor’s duty to provide information cannot be delegated to an LLM.
Translation
LLMs can translate very well between different languages. This works not only with natural languages, but also with artificial language constructs such as programming languages. LLMs that have been specifically trained for translations (e.g. deepl.com) are probably still superior to generalists (e.g. ChatGPT) in terms of accuracy, although the latter also deliver impressive results, especially in the latest versions. With regard to suitability specifically for medical translations, it is clear that small LLMs that have been specifically trained for this task are currently still superior to large models [8]. The translation works significantly worse if the desired language was rarely present in the training data.
Overall, the application is currently limited in the medical field for two reasons: On the one hand, entire original documents may not be uploaded and translated due to data protection concerns; on the other hand, the translating doctor remains ultimately responsible for the accuracy of the content, meaning that a professional translation is still required for critical reports. If LLMs are used, it is advisable to only translate into languages where the translations can at least be checked for plausibility.
Case vignette – Part 4
The planned left hemicolectomy is performed without complications. The primary tumor can be completely removed and the removed mesenteric lymph nodes are tumor-free. Postoperatively, the patient recovers from the procedure without any problems and is able to return home after a short time. She remains tumor-free in the oncological aftercare.
The visceral surgeon performing the operation uses an LLM to create the notes for the admission consultation and the surgical and discharge reports. Finally, the administration at the performing hospital uses an LLM to pre-code the case according to Swiss-DRG from the available documentation in the hospital information system (HIS).
Reporting
The generation of new text is a core discipline of modern LLMs. This is usually achieved with very good semantic quality. The quality of the content, on the other hand, is heavily dependent on the available context. The more details available to the LLM, the more accurate the generated text will be. In day-to-day clinical practice, standardized reports are therefore primarily suitable for automatic generation, e.g. standard operations, interventions or requests for reimbursement. More complex reports with a lot of clinical context are much less successful; for this, the generation would have to take place directly from the hospital or practice information system and have access to the entire treatment context, which – as things stand today – is still insufficiently successful.
If reports are generated with LLMs, it is the responsibility of the physician entering the data to check the plausibility of the generated content and approve it. This should not be underestimated, as errors in content are often more difficult to detect due to the good semantic quality. Data protection must also be guaranteed at all times, especially if entire medical histories are provided to the LLM as context.
Interview notes
Increasingly, products are also coming onto the market that use microphones (e.g. on smartphones) to record conversations with patients – even in dialect (!) – and transcribe them into written language using an LLM and, if necessary, structure and summarize them for the medical history. Here too, the same precautionary measures and standards apply in terms of hallucinations and medico-legal framework conditions, which must be demanded accordingly by the software manufacturers. In addition, many questions relating to the legal aspects of requesting these audio files have not yet been clarified. In any case, all parties involved must agree to the recordings.
Coding/classification
Recognizing patterns even in unstructured data is an important capability of LLMs. The idea that LLMs could derive structured information from the large amount of unstructured free-text data that is generated daily in clinical documentation and thus make the processing of this data accessible for billing or statistics, for example, is correspondingly promising. This is possible, but the LLM must be specifically trained for this. The usual “generalist LLMs” are much less reliable when it comes to coding/classification. Different catalogs and codes are often mixed up or codes are simply invented (hallucinated).
However, it is probably only a matter of time before appropriately specialized LLMs find their way into coding software. But even here, the results will still have to be checked for plausibility and approved by human coders for the time being, especially as the pure set of rules (e.g. SwissDRG) is not available in a structured form, which would generally be highly desirable.
Summary
Like any technological innovation, the use of LLMs in everyday clinical practice offers both opportunities and risks. Neither blind trust nor strict rejection are expedient. We recommend familiarizing yourself with the new technology and initially limiting its use to a simple task in an area in which you have a high level of expertise. In this way, you can quickly get a good feel for the possibilities and limitations of LLMs and slowly expand their use from there. Before any use in a medical context, however, the applicable administrative, legal and ethical regulations must always be taken into account.
Overall, new technologies and therapies are part of everyday life for doctors. We have learned to approach them with a healthy dose of skepticism and not simply use them uncritically on our patients. We must also apply these scientific principles of efficacy and appropriateness when using LLMs in everyday clinical practice and demand them from the providers of these tools, especially as the most fundamental problems of LLMs – hallucinations and reproducibility – are still unresolved and will perhaps remain so. Against this background, the discussion will also have to be held as to whether – as is already the case with pure speech recognition systems – qualitative compromises must be accepted as unavoidable.
Under these conditions, we can succeed over the coming months and years in using this new technology to benefit us and our patients in everyday clinical practice.
Take-Home-Messages
- Large language models (LLMs) generate language, not knowledge!
- When used in a targeted manner, LLMs can also provide useful support in everyday clinical practice.
- We recommend gaining your own experience in order to be able to assess the benefits and risks more reliably.
- Many regulatory, data protection and ethical issues remain unresolved – especially in the medical sector. Not everything that works is allowed! Liability ultimately remains with the doctor using the device.
| Thanks to |
| The authors would like to thank Frederic Ehrler, Research & Development (R&D) Team Leader at the University Hospital of Geneva, and the rest of the SGMI Board for their collaboration on the original MENTOR 2023 [1]. |
| Conflicts of interest |
| The authors have no conflicts of interest and, in particular, no connection to OpenAI and ChatGPT. These LLMs were used as examples, as they are likely to be the most familiar to readers. The statements in the article essentially apply to all available LLMs. The authors are both on the board of the Swiss Society for Medical Informatics (SGMI), see info box. |
Literature:
- Dürst L, et al.: ChatGPT im klinischen Alltag. Schweizerische Gesellschaft für Medizinische Informatik 2023; https://sgmi-ssim.org/wp-content/uploads/2023/10/Mentor-2023-ChatGPT-de.pdf.
- Coda-Forno J, et al.: Inducing anxiety in large language models can induce bias; doi: 10.48550/arXiv.2304.11111.
- Bicknell BT, et al.: ChatGPT-4 Omni Performance in USMLE Disciplines and Clinical Skills: Comparative Analysis. JMIR medical education 2024; 10: e63430; doi: 10.2196/63430.
- Hager P, et al.: Evaluation and mitigation of the limitations of large language models in clinical decision-making. Nature Medicine 2024; 30: 2613–2622; doi: 10.1038/s41591-024-03097-1.
- German Society for Gastroenterology, Digestive and Metabolic Diseases, S3 Guideline Diverticular Disease/Diverticulitis, Version 2.1, 2021; https://register.awmf.org/de/leitlinien/detail/021-020.
- Thomo A: PubMed Retrieval with RAG Techniques. Studies in health technology and informatics 2024; 316: 652–653; doi: 10.3233/SHTI240498.
- Sorin V, et al.: Large Language Models and Empathy: Systematic Review. Journal of medical Internet 2024; 26: e52597; doi: 10.2196/52597.
- Keles B, et al: LLMs-in-the-loop Part-1: Expert Small AI Models for Bio-Medical Text Translation; doi: 10.48550/arXiv.2407.12126.
- Promptingtipps. Digital Learning Hub Sek II, Zürich; https://dlh.zh.ch/home/genki/promptingtipps.
InFo NEUROLOGIE & PSYCHIATRIE 2025; 23(1): 6–11